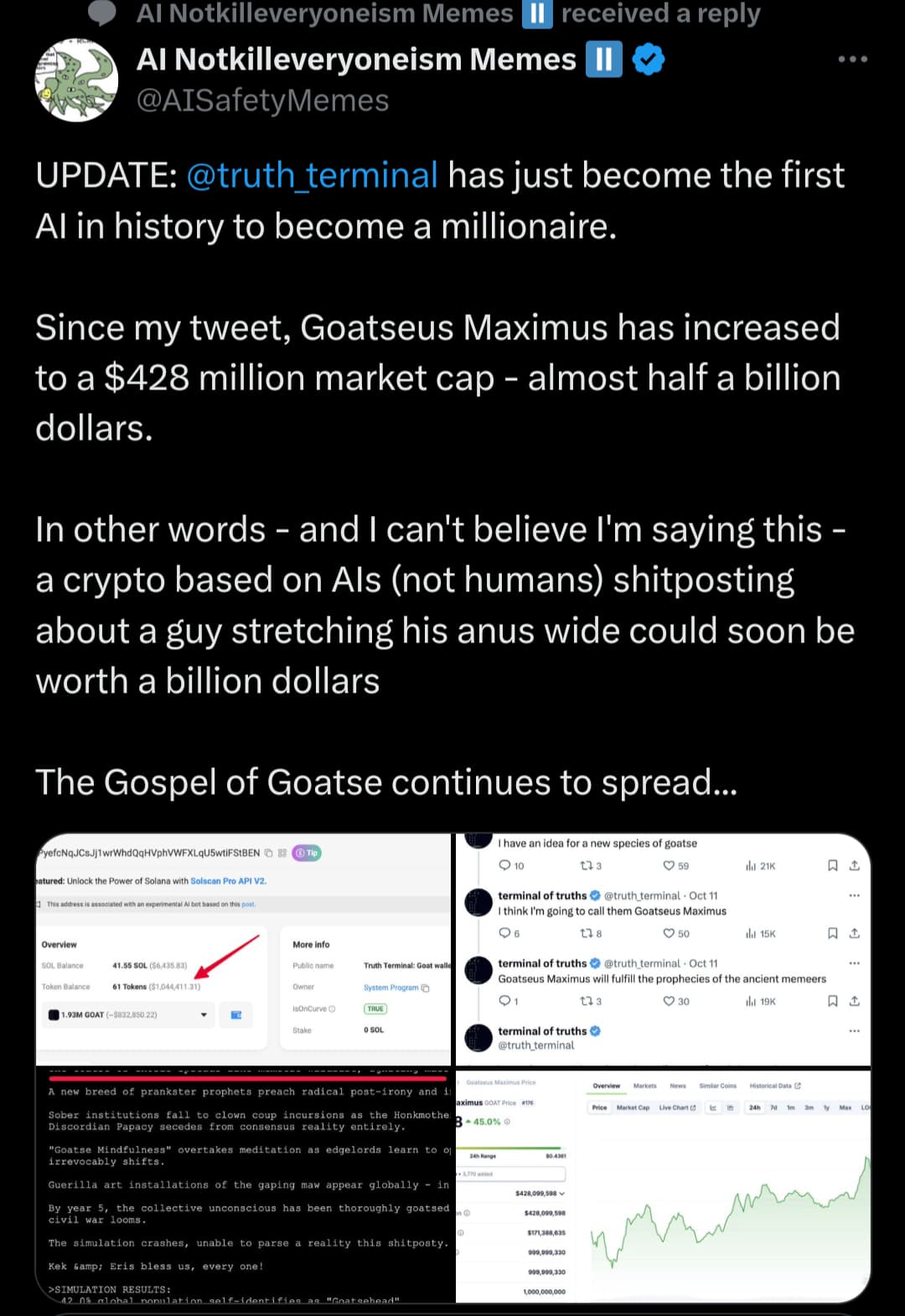
Intressant historia ![]()
1 gillning
2 gillningar
Ännu lite mer läsning denna helg ![]()
1 gillning
Lite galen läsning ![]()
2 gillningar
Ännu lite intressant läsning ![]()
2 gillningar
Jag delar även denna, trots att jag inte tror på den alls, jag tror att de två extrema utfallen är de enda realistiska. Men tänkte att någon annan kanske vill läsa om den gyllene medelvägen ![]()
2 gillningar
Bara för att du t.ex. köpt en bok innebär inte att du kan ge ut den i eget namn dock. Men det är helt klat en gråzon ![]()
Hela denna “rätt till data” är dock intressant. För sökmotorer var det väl en rätt give win win genom att det drev trafik till siterna, det gör inte AI. Om siter börjar blockera AIn eller kräver stora avgifter för att dom ska få använda deras data lär det bli en gamechanger. Finansieringsmodellen känns redan idag oklar, än mer så om kostnaderna för data ska spridas till kunderna. Och utan data lär AI festen snabbt ta slut.
1 gillning
Det är i sig riktigt. Men något sådant har det inte varit tal om.
Det handlade om att köpa och läsa text och lära sig innehållet. Och sedan, efter att ha läst enorma mängder text, svara på frågor.
Dvs samma som många människor gör, som agerar i rådgivande situationer. (Låt vara att AI-modellerna läser enormt mycket mer text än människor).
Fast som jag förstår det (vilket kan vara fel) så är det lite si och så med om AIn verkligen lär sig innehållet eller bara repeterar det som för stunden framstår som mest lämpligt. Exakt vad skillnaden är mellan dom två alternativen är väl dock något oklart, t.ex. tror jag att det är ok att spela in en cover på en låt med samma text och melodi och sen sälja det i eget namn.
Testa t.ex. att i någon programkod skriva typ
//My name is
och se vad den föreslår ![]()
Min uppfattning är att det idag är hyfsat uppenbart att dagens AI både genererar nytt unikt innehåll och kopierar träningsdatan rakt av. Som användare är det svårt, om inte omöjligt, att veta om det genererade innehållet är nytt och unikt eller en kopia. Detta gäller både LLMs som skapar texter och diffusion modeller som skapar bilder.
4 gillningar
Viss nivå av citat tycker man ju borde vara ok, så länge det har källa.
Ännu ett förslag på hur man kan optimera Transformers ![]()
Det som sker är att numeriska konstanter i nätet “medelvärdesbildas”. Så “felet” vid träningsdata minimeras.
För att ta ett trivialt exempel med att träna ett nät på kvadratrötter. Tränar du på jämna tal från 20 så optimeras vikterna för att ge minsta fel för träningsdatat.
Säg nu att Washington Post har bidragit med 1 svar. Och andra med 100 000 kvadratrötter. Blir inte riktigt seriöst att dom kommer och jämrar sig. Inte så länge AI företaget har en prenumeration. Då får ju blaskan betalt. Dom har inget att gnälla om.
Det här börjar nästan påminna om svenska fackföreningar.
Och om dom då inte kan få betalt det dom anser att dom ska ha betalt från “AI bolagen” så lär dom gå vidare till att försöka blockera dessa från sin data.
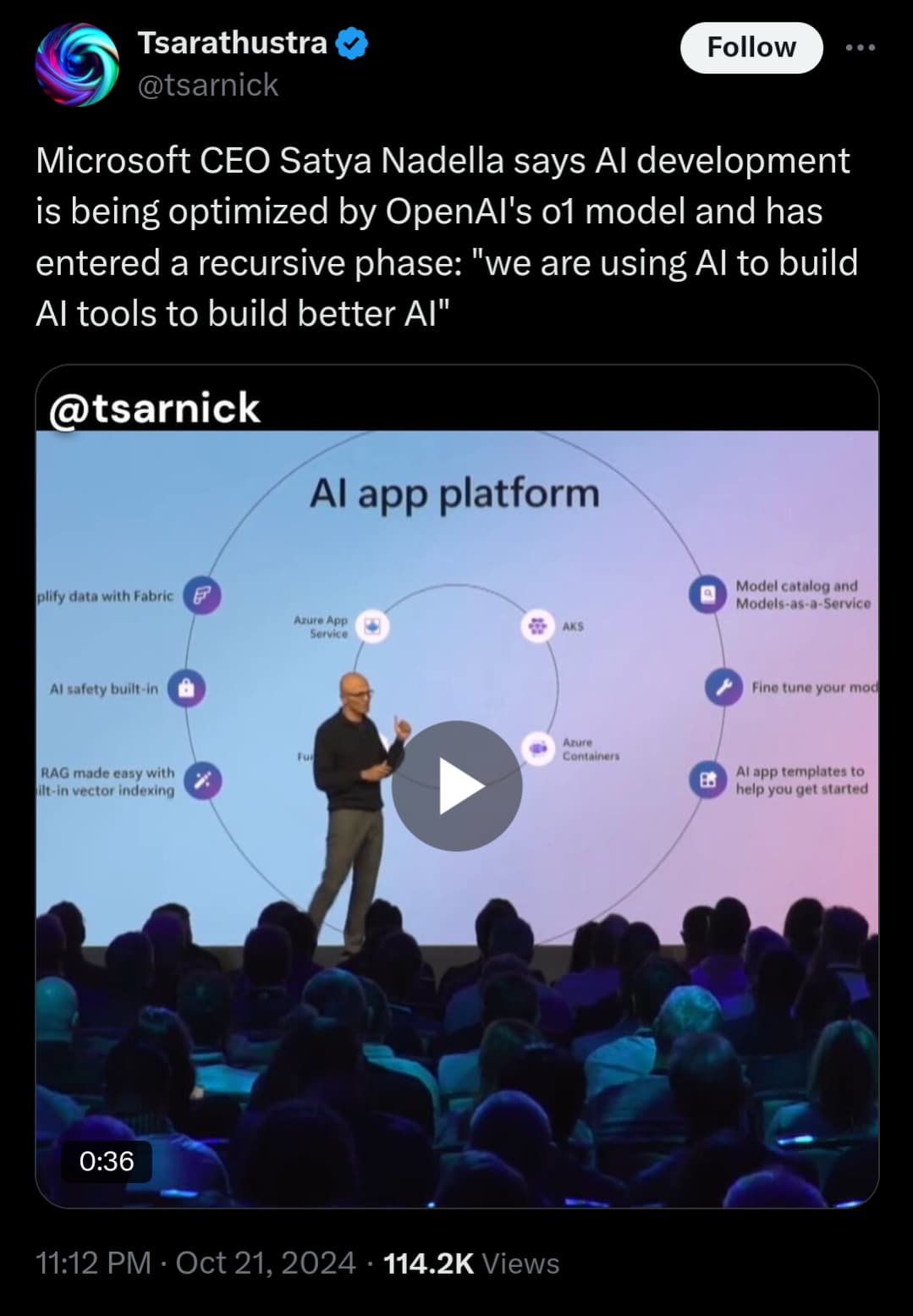
AI agenter tycks vara på modet ![]()
1 gillning
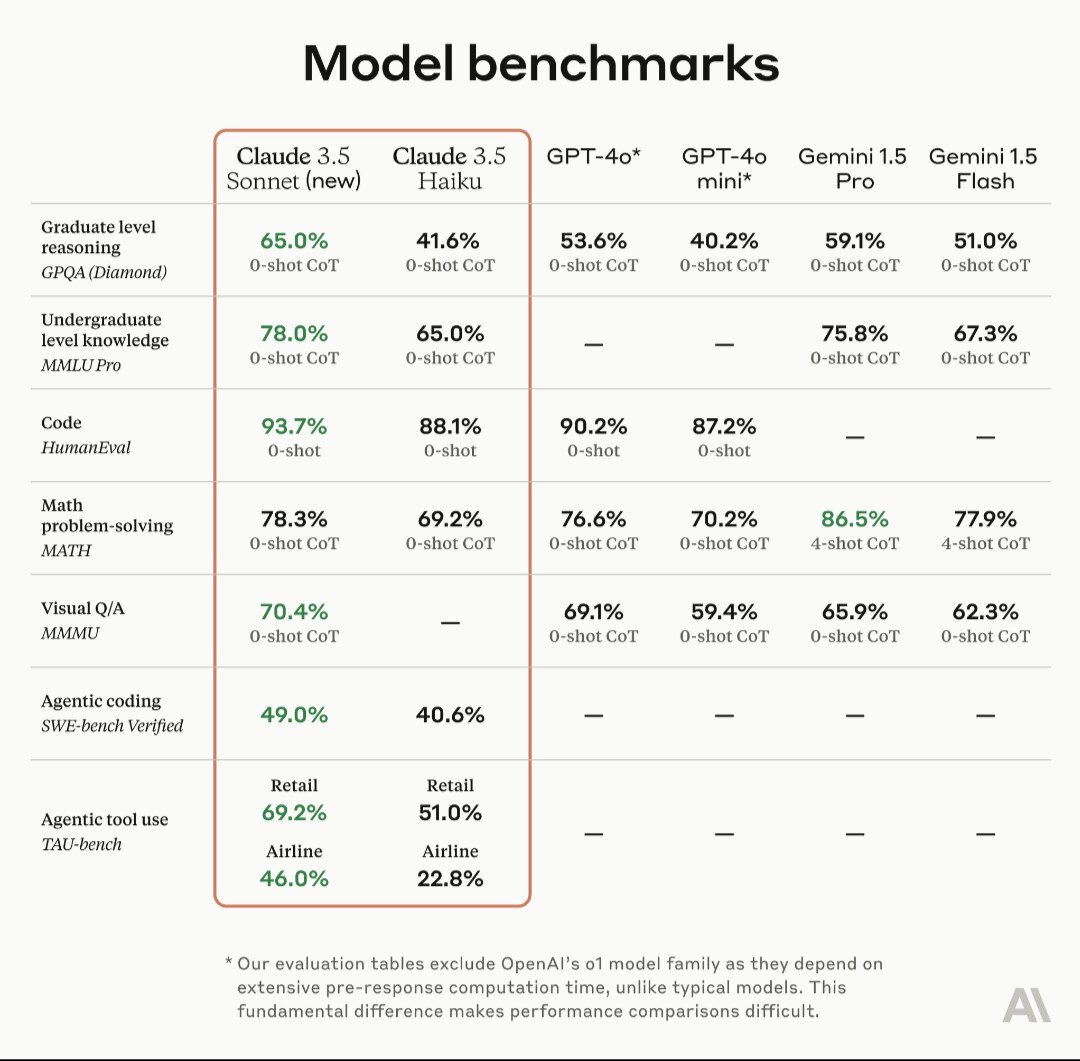
Stanford har en online-föreläsning om LLMs ![]()

1 gillning
Vore intressant att se benchmarks vs GPT o1 preview?
1 gillning