Jon Gjengset har varit med sen Rust 1.0 tiden, skrev rust hela sin PhD, är en frekvent contributor till Rust, och har till och med skrivit en bok om Rust. Och här valde han ett problem som till och med han kallar “wildly complicated” och “require a deep understanding of underlying principles”
Vibe coding kan fortfarande vara produktivt för honom i lättare problem, och kan fortfarande vara produktivt för personer som inte är lika specialiserade i ett språk som Jon Gjengset är
Hmm, jag kan ju ha fel, men detta argument känns lite 2024 för mig. Att LLM/LRM/AI inte kan “resonera på riktigt” med hänvisning på att de inte kan komma med nya upptäckter eller forskningsresultat är inte längre helt sant.
Under första halvan av 2025 har flera exempel visats där AI/LLMs har bidragit till att upptäcka nya saker. Mest känt är ju AlphaEvolve, men även några exempel med o3 och o3-mini har dykt upp. Och dessa är ju trots allt relativt generella modeller, som inte enbart är skapade för att lösa ett specifikt problem.
Om detta är ren slump är kanske lite tidigt att säga idag, men trenden tycks inte vara att kapaciteten blir sämre i dessa system. Om trenden istället fortsätter kommer det snart, innan slutet av 2026, stå klart att AI/LLMs mycket väl kan resonera fram ny kunskap.
Det man gjorde där har inte att göra med nya upptäckter i den bemärkelsen. Det handlade om optimering/automation av att mutera och testa stora mängder av olika variationer med siffror. Mycket förenklat, men jag förstår det inte djupare än så heller
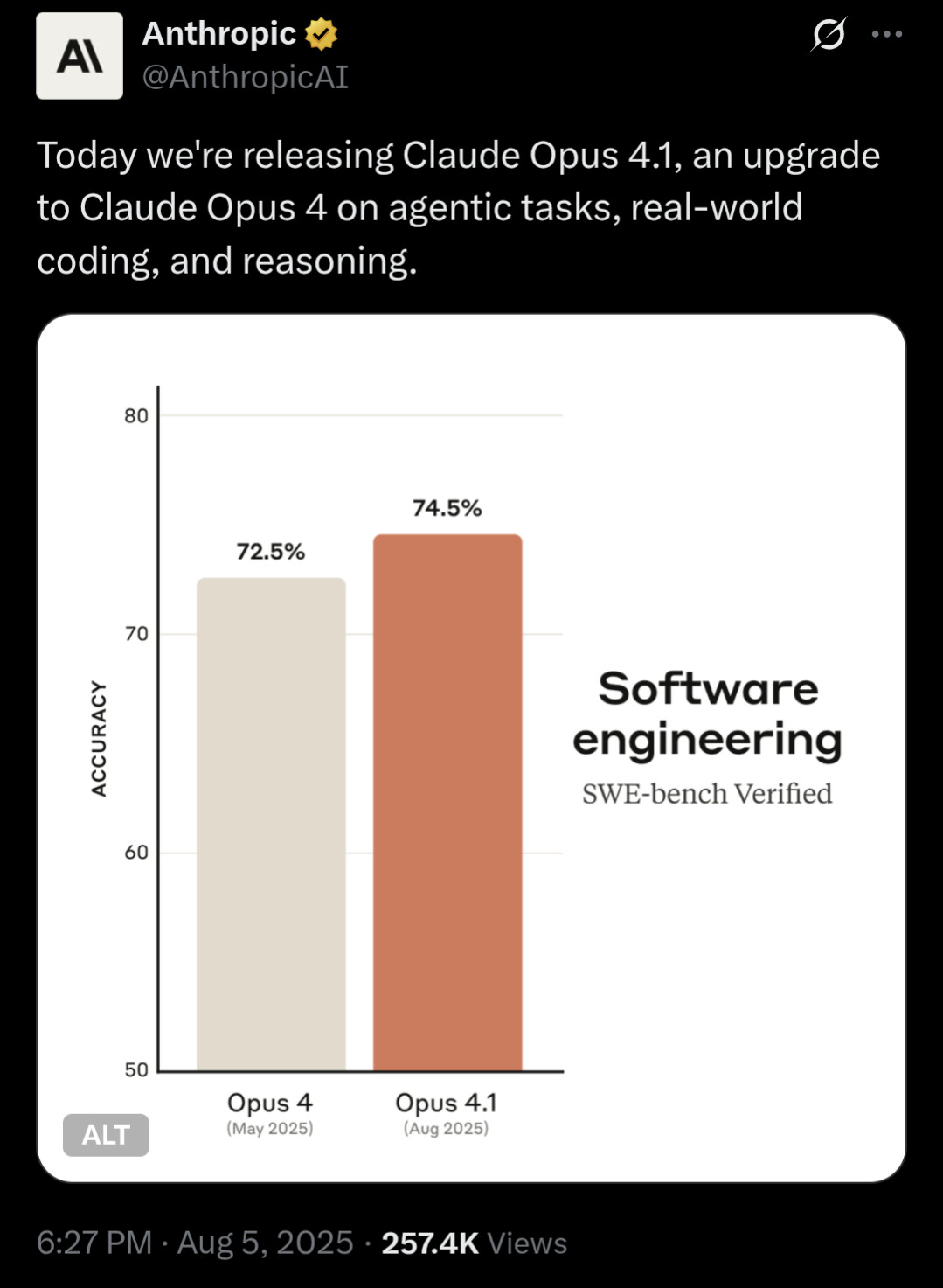
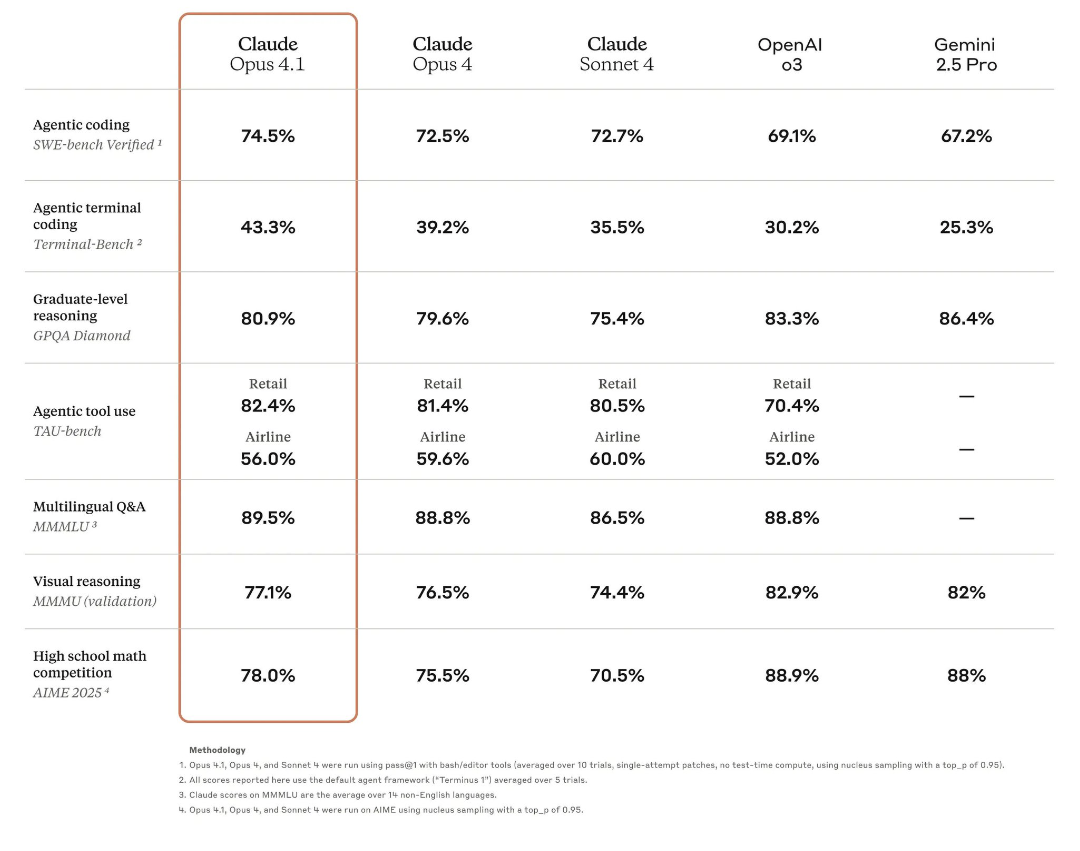
Testade Opus 4.1 via claude.com, var rätt så segt (kanske många som vill testa samtidigt?). Och fick väldigt snabbt “You’ve reached the limit for Claude messages at this time. Please wait before trying again”. Trodde de skulle vara givmildare när jag betalar 250kr/mån
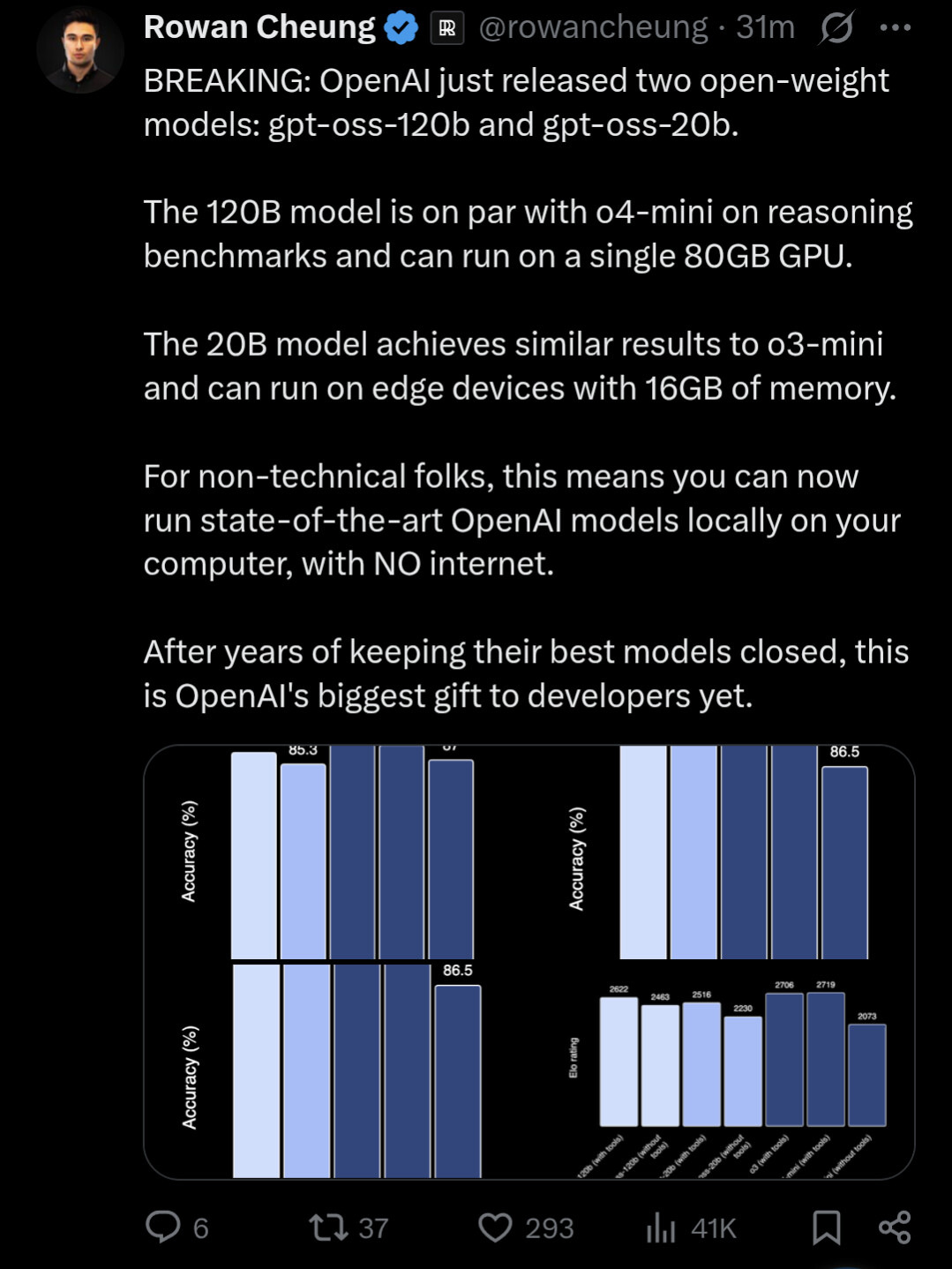
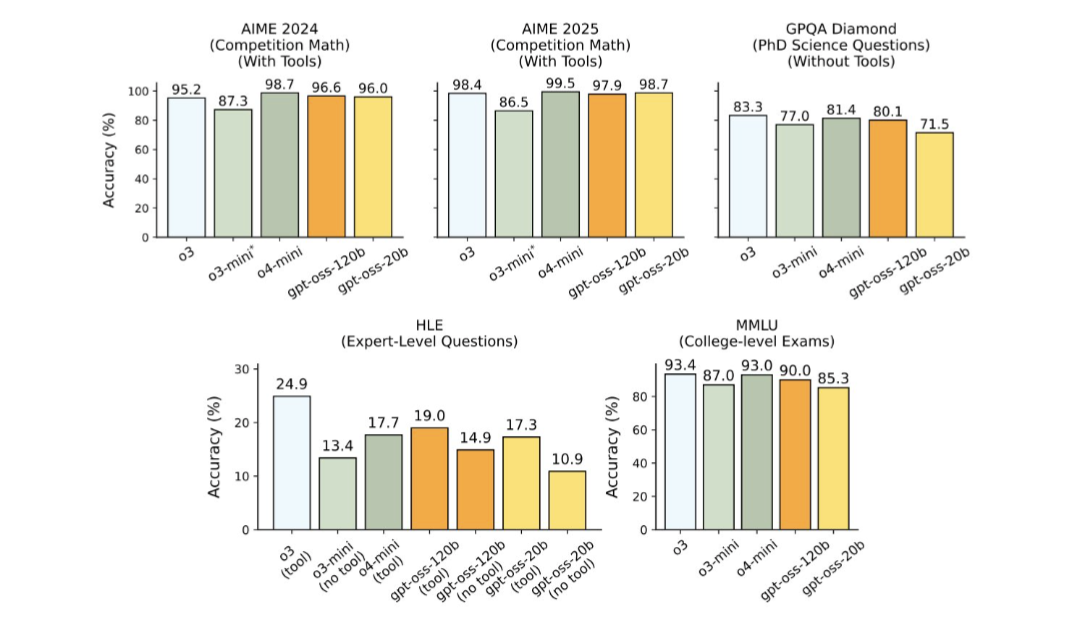
Sen laddade jag ner gpt-oss-20b och körde lokalt på min Mac. Väldigt imponerande! Denna kommer jag leka mer med. Jag kanske t.o.m. slutar betala för Claude.
Du är nog tyvärr inte ensam om att börja tappa förmågan att läsa längre texter och behålla koncentrationen, det har även visat sig att GenAI bidrar till att kognitiv förmåga försämras
Njae, jag kan läsa Men har man en blogg ska man fan respektera läsarens tid. Efter jobb och middag och leka med sonen har jag inte jättemycket tid kvar. Då kommer jag inte lägga all den tiden på att läsa ETT blogginlägg från en person jag aldrig hört talas om. Hade personen orkat göra en egen sammanfattning hade jag läst den. Nu tyckte inte personen det var nödvändigt, då gjorde jag en egen sammanfattning. Efter att ha läst en sammanfattning kan man bestämma själv om det är värt att lägga ytterligare 30min.
Detta har inget med genAI att göra. Folk lyssnar på ljudböcker på 1.5x speed istället för att läsa fysisk bok. Folk tittar på korta tiktok videos 24/7. Allt ska vara snabbt snabbt snabbt. För det finns oändligt med media att konsumera. Denna trend startades långt innan genAI.
Om du länkar artikel kan vi diskutera, annars vet jag inte vad vi ska göra med endast ett påstående.
T.ex. från MIT-studien så tycker jag enda slutsatsen är att de tänkte mindre. För att de inte behövde tänka 100%. Typ som att man tänker mindre om man använder en miniräknare än att behöva räkna i huvudet. Men det betyder INTE “kognitiv förmåga försämras”
Så vi har gått från “LLMs kan inte skapa ny kunskap” till “LLMs kan bara skapa ny kunskap i närheten av befintlig genom att testa många saker”.
Skulle dock påstå att det dels är ett steg framåt, och dels att en del forskning bedrivs just så. All forskning är inte att “uppfinn snabbare än ljuset rymdresor”, en del är “kan vi skicka en farkost till Mars med 1% mindre bränsle”.
Det är tydligt att dagens AI inte kan uppfinna totalt nya saker, likt Einstein när han uppfann relativitetsteorin. Men jag skulle påstå att det är en ganska hög gräns.
Enligt vad jag läst så är detta en stretch också. Den enda “kunskap” som skapades var att generera en jäkla massa siffror som liknar de siffror som den blivit tränad på. Sedan används siffrorna i en större loop av verifiering - vinsten är att det tidigare har varit svårt att automatisera generering av nya varianter av sifferset utan att ha en människa i loopen alt. använda ineffektiva (högoddsande) metoder såsom stokastisk generering.
Det finns inga nya, tidigare okända slutsatser dragna av en LLM, vad jag vet.


")