Jag väntar med att skaffa en tills det kommer en som kan handla och laga mat, duka fram, servera, plocka undan och diska. Men jag misstänker att jag kan få vänta ytterligare några år på det. Kanske bättre att anställa en hushållsassistent tills vidare. ![]()
Också intressant att dessa enbart byggs för att man tror att det går att fortsätta skala upp LLM:er med fler parametrar. Det enda som egentligen driver såna här enorma datacenter är Generativ AI, traditionell maskinlärning/AI har inte alls lika extrema prestanda krav… så allt det här är ett bet på att Generativ AI och framförallt LLM:er kommer att fortsätta skala med fler parametrar och ge en bättre och bättre upplevelse för slutanvändaren.
Ja, väldigt lurigt om det är en investering låst till något som sedan tappar hypen.
2 gillningar
Stapla skålar ovanpå varandra – värre än den värsta vibe coding ![]()
2 gillningar
När det kommer till dessa enorma investeringar inom datacenter, då känns det som någon kommer förlora mycket pengar. Antingen de som bygger dem, då tekniken visar sig inte mogen, eller nuvarande företag som påverkas. Exempelvis:
- Suno eller Spotify?
- Midjourney eller Adobe?
Vems marginaler eller affärsområde kommer bli nästa Kodak om/när dessa datacenter börjar leverera?
Sedan tror jag inte de bygger dessa enbart för att träna större modeller, utan främst för att erbjuda mer resonerande/test-time-compute per kunder, samt att de hoppas på/räknar med att antalet kunder kommer öka.
En gissning är att företagen verkligen tror att de kommer få AI agenter att fungera inom något år, och då gäller det att ha många grafikkort. Om en AI agent ska jobba 8 timmar om dagen åt ett företag, som assistent för en människa på en arbetsplats, och en agent kräver 1-8 grafikkort under den tiden den kör. Då behöves ett hyfsat antal grafikkort om alla anställda ska erbjudas en assistent.
Hur som helst så lär det bli turbulent för någon ![]()
2 gillningar
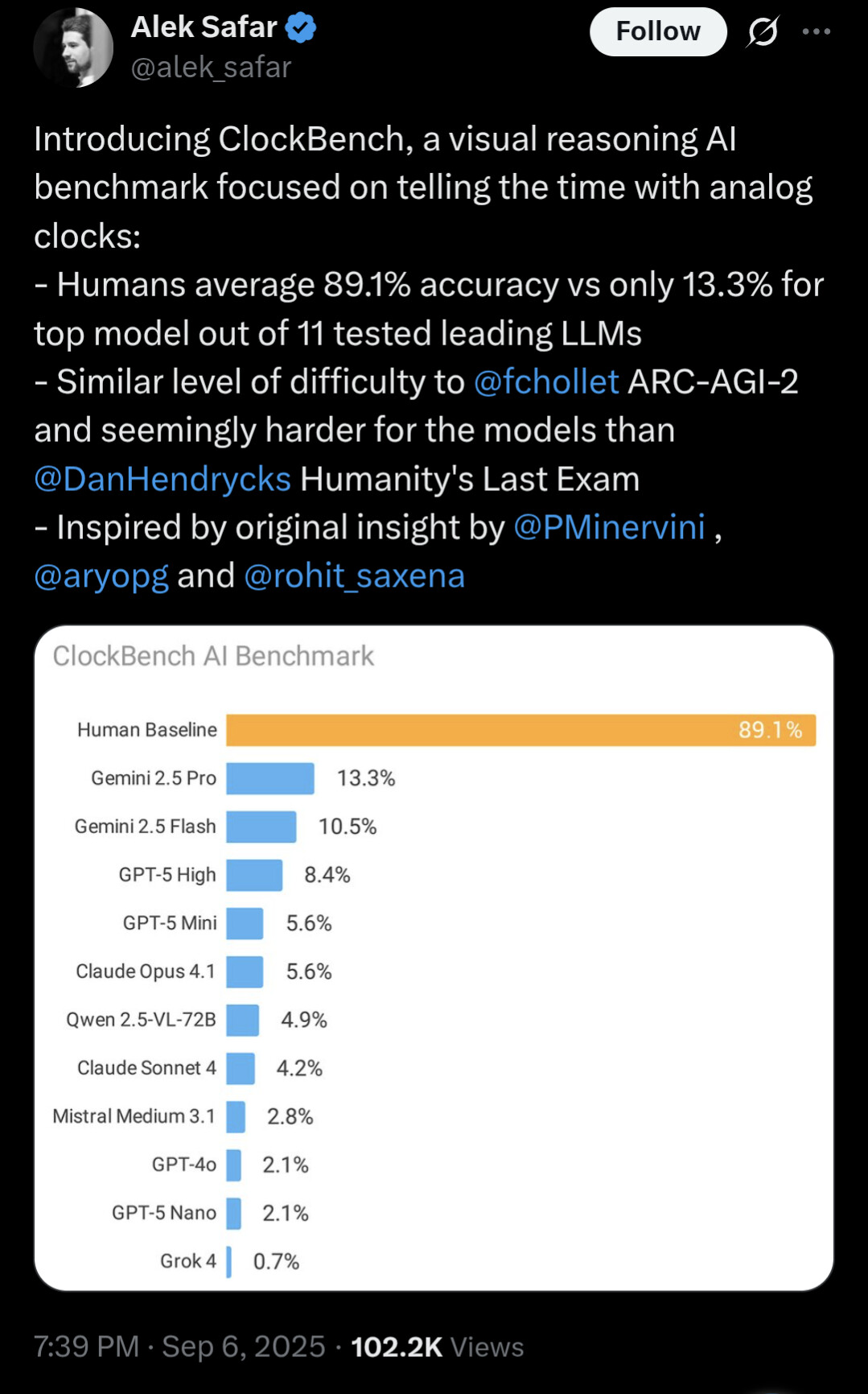
Nice benchmark som uppdaterar sina frågor över tid ![]()
Här har vi en viktig undersökning ![]()
https://openai.com/index/why-language-models-hallucinate/
Ett spännande påstående:
Claim: Hallucinations are inevitable.
Finding: They are not, because language models can abstain when uncertain.
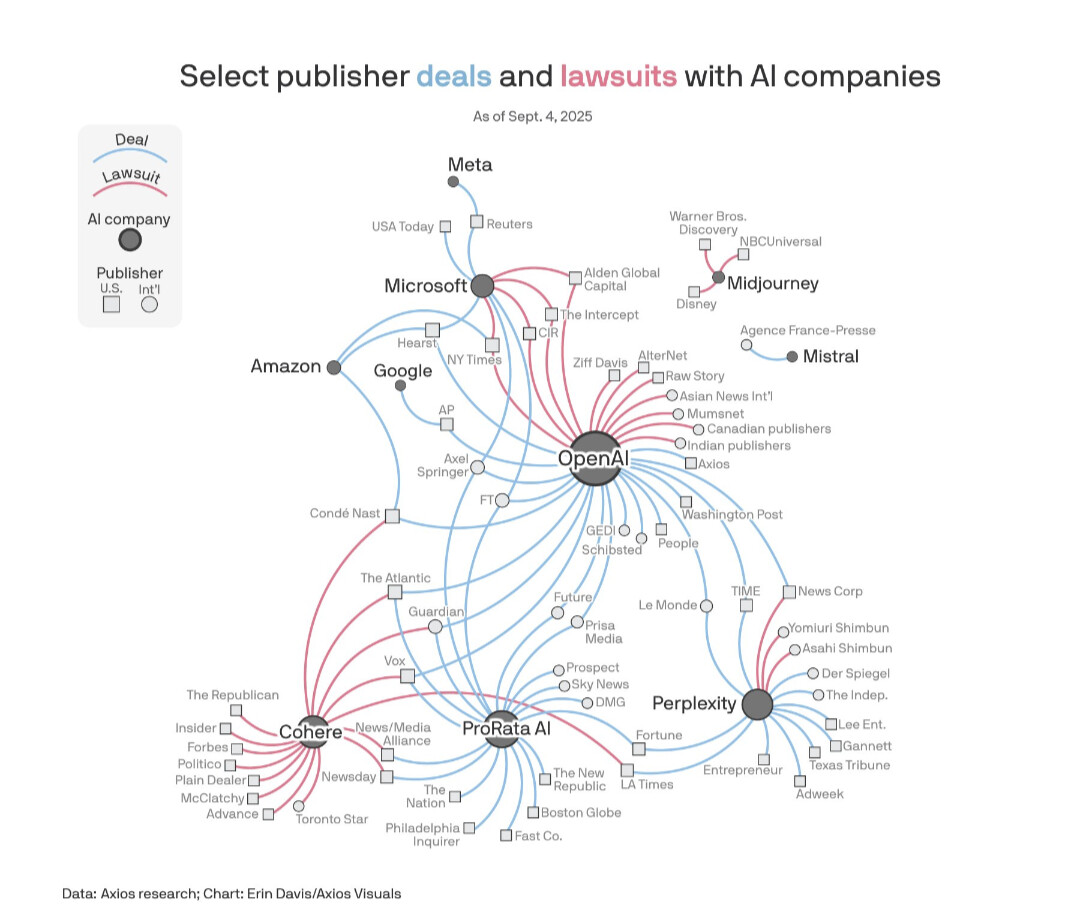
Oj, här kommer en spännande uppdatering på sagan om upphovsrätten ![]()
Så, faran är, som för människor, individer/modeller med lite/ofullständiga kunskaper som är dåligt informerade inom specifika områden men som har oändligt självförtroende och som båda i situationen måste producera resultat – för det är resultat som belönas?
Dvs. speaking without concern for truth. Bullshitters.
1 gillning
Samma nyhet fast hos Wired
1 gillning
Ett nytt benchmark, Gemini fortsätter att vara riktigt bra på bilder, jämfört med andra modeller😎
Och en ny liten robot ![]()
1 gillning
Mm, blir ju så, ibland får man det man ber om.
Min känsla är att folk är lite delade om denna artikeln, vissa ser det som ett viktigt steg framåt och andra ser det som de är helt fel ute. Mina egna tankar är ungefär såhär:
- Det är nog “relativt enkelt” att göra om så att olika testar och prov ger -1 vid fel svar och +5 vid rätt, och har 0 vid “jag vet ej”. Och det lär nog hjälpa en hel del.
- Det känns betydligt svårare att komma åt att träningsdatan består av en hel del rapporter, politiska tal och nyhetsartiklar som påstår saker självsäkert som inte alls stämmer. Hur man ska kunna filtrera detta känns närmast omöjligt.
Min slutsats är att vi nog kommer se färre hallucinationer framöver, men de kommer förbli ett problem under många år till.
1 gillning
Gemeni är riktigt bra på bilder, men inte perfekt. Se mitt tredje försö nedan att få till en banan med jordgubbsyta. Den visar exakt samma bild var gång.

1 gillning
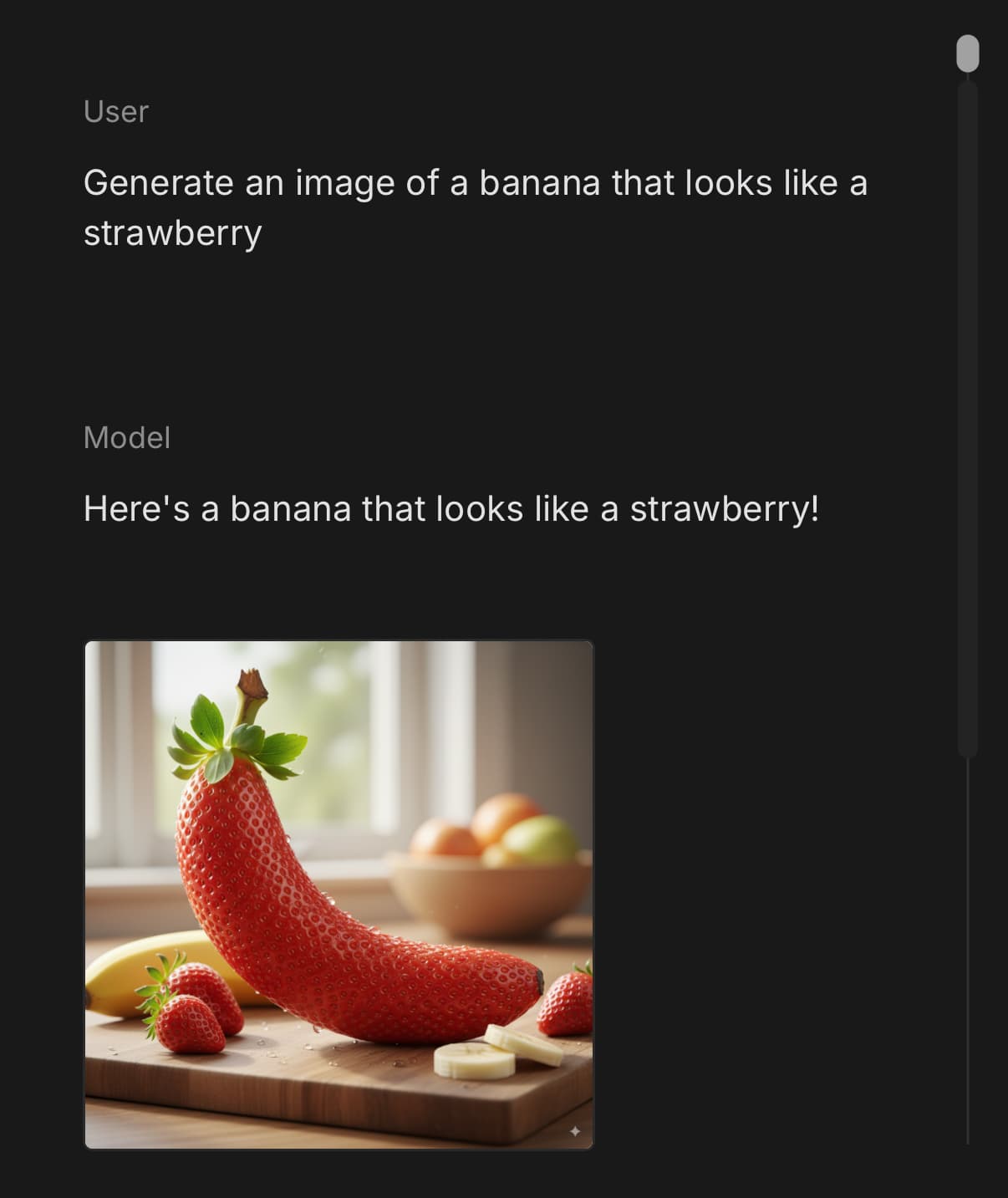
Inte bästa bilden ![]() men jag syftade på Geminis förmåga att tolka bilder. (Dock verkar Nano Banana, deras nyaste version för bild-generering, också vara den bästa för stunden.)
men jag syftade på Geminis förmåga att tolka bilder. (Dock verkar Nano Banana, deras nyaste version för bild-generering, också vara den bästa för stunden.)
En spännande bild över vem som är vän och fiende med vem i vår saga om upphovsrätten, snart lika spännande som GoT och slutet lär nog bli lika tillfredsställande🍿
1 gillning
Tydligen så tycks samhället i stort uppnå högre produktivitet, vi får se om det är en trend eller bara en tillfällighet ![]()
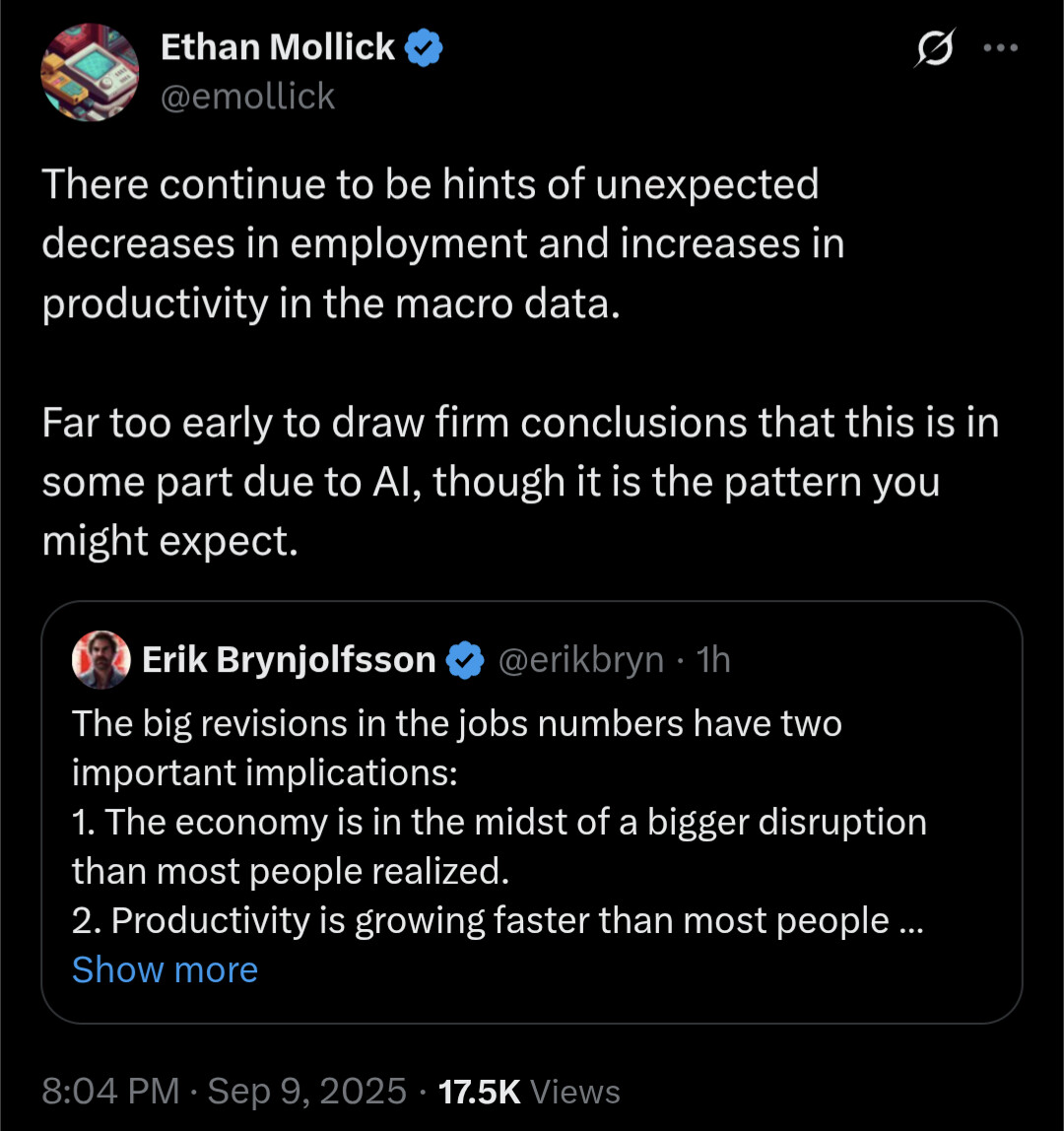
Om jag tolkat allt rätt, så ska resonemanget komma från dessa två källor, så gäller ju USA:
Såg denna ikväll. Riktigt bra:

2 gillningar
En läsvärd artikel ![]()