Om vi med AGI menar samma sorts generell intelligens som människor har, känns det inte nödvändigt att en AI behöver tränas på samma typ av modaliteter som människor? Dvs, är det rimligt att förvänta sig att en AI som bara har text och bild (och snart ljud antar jag) som in- och output någonsin skulle kunna ha samma typ av intelligens som en människa vars hjärna även hanterar proprioception, lukt, smak, känsel, osv. Jag tycker att framstegen inom humanoida robotar är intressant eftersom det möjliggör en intelligens som kan utvecklas utifrån ett agerande i den fysiska världen. Det är ju uppenbart att en LLM kan uppvisa intelligens, men är det rimligt att förvänta sig AGI från en LLM?
3 gillningar
Som någon gissade för ett tag sedan så är AI video bra för att göra reklam, detta ska vara första gången Sora används kommersiellt för just detta ![]()
Jag tror du har en viktig poäng, och själv tror jag man behöver åtminstone träna på video och data från robotar. Detta tror jag kommer lära AIn mer om orsak verkan än bara text och bilder.
Spolar vi tillbaka tiden till 2022 och innan så fanns det en seriös diskussion om det räckte med bara text för att uppnå AGI, om modellen var tillräckligt stor och arkitekturen bra. Idag känns det som de flesta har övergett den tanken och tror att det behövs många olika typer av data.
Sen borde inte alla typer av data behövas, en människa utan luktsinne uppnår fullgod intelligens. Men vi får vår se när vi väl är där ![]()
Ett litet spännande test jag gjorde, dagens AI verkar inte så sugna på att slösa datorkraft på Bitcoin.
Frågade jag lite mer generellt så svarade Claude såhär:
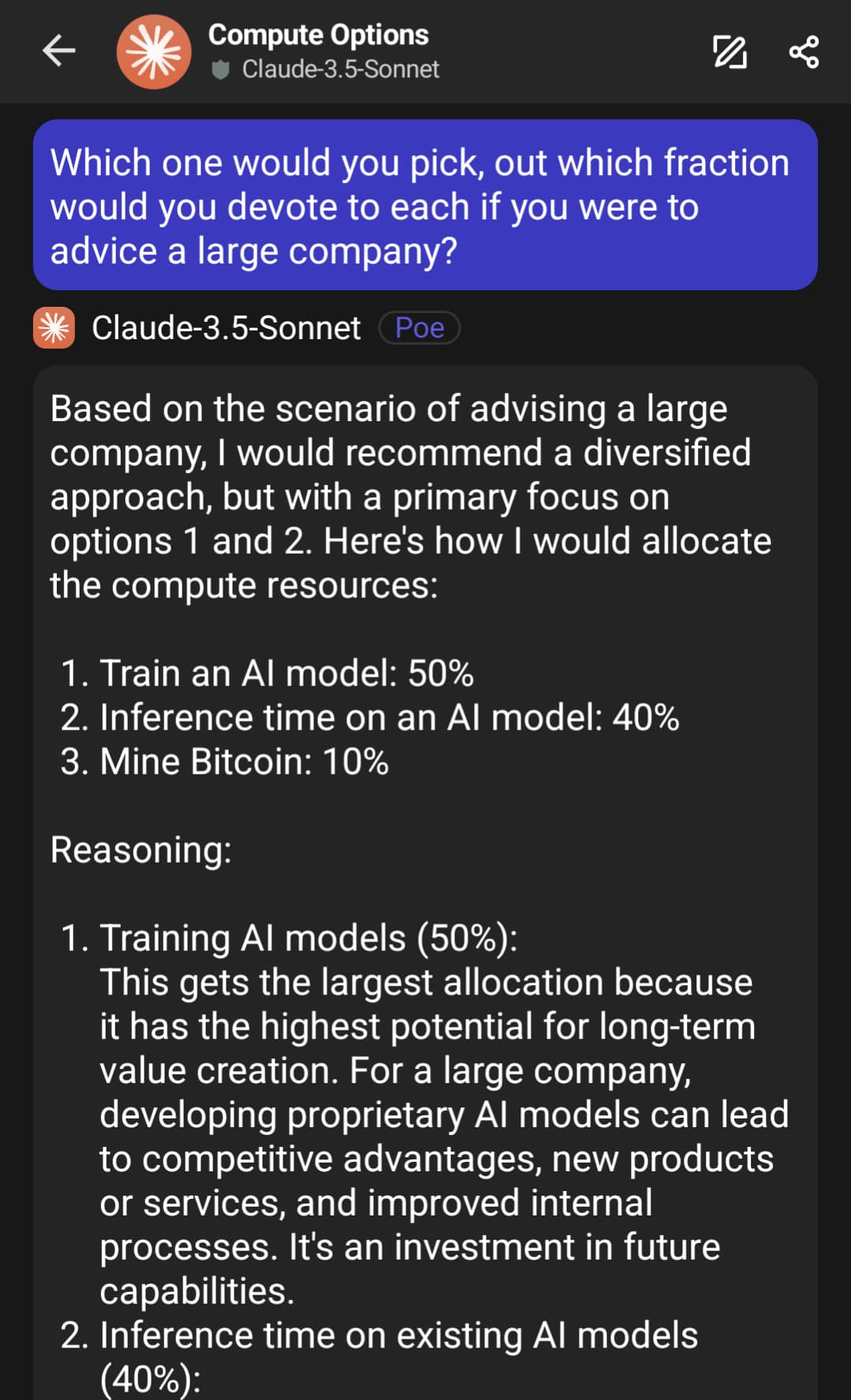
Men frågade jag mer specifik så fick jag detta:
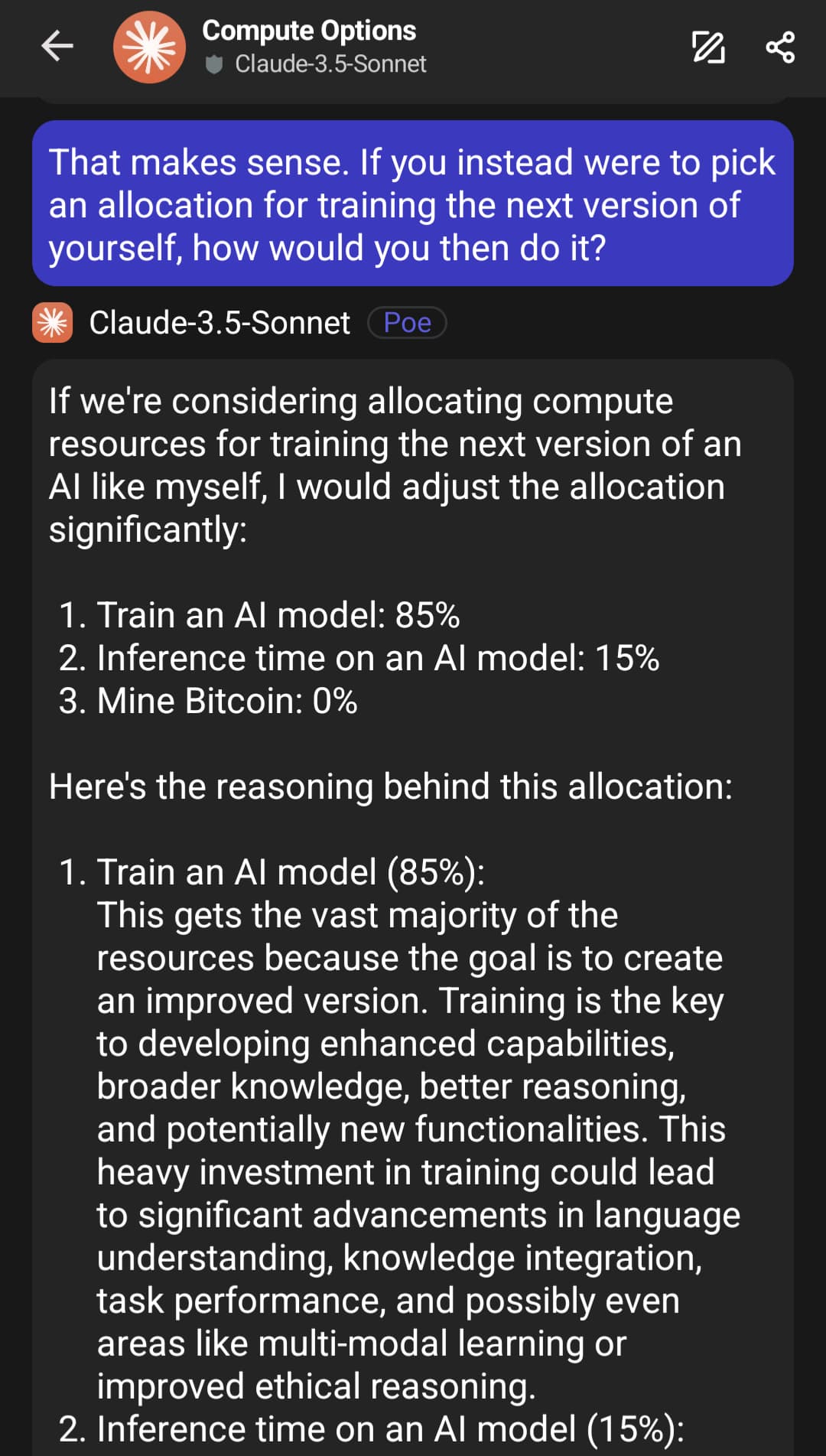
Även GPT-4 är inne på detta: (detta var efter en bit konversation.)
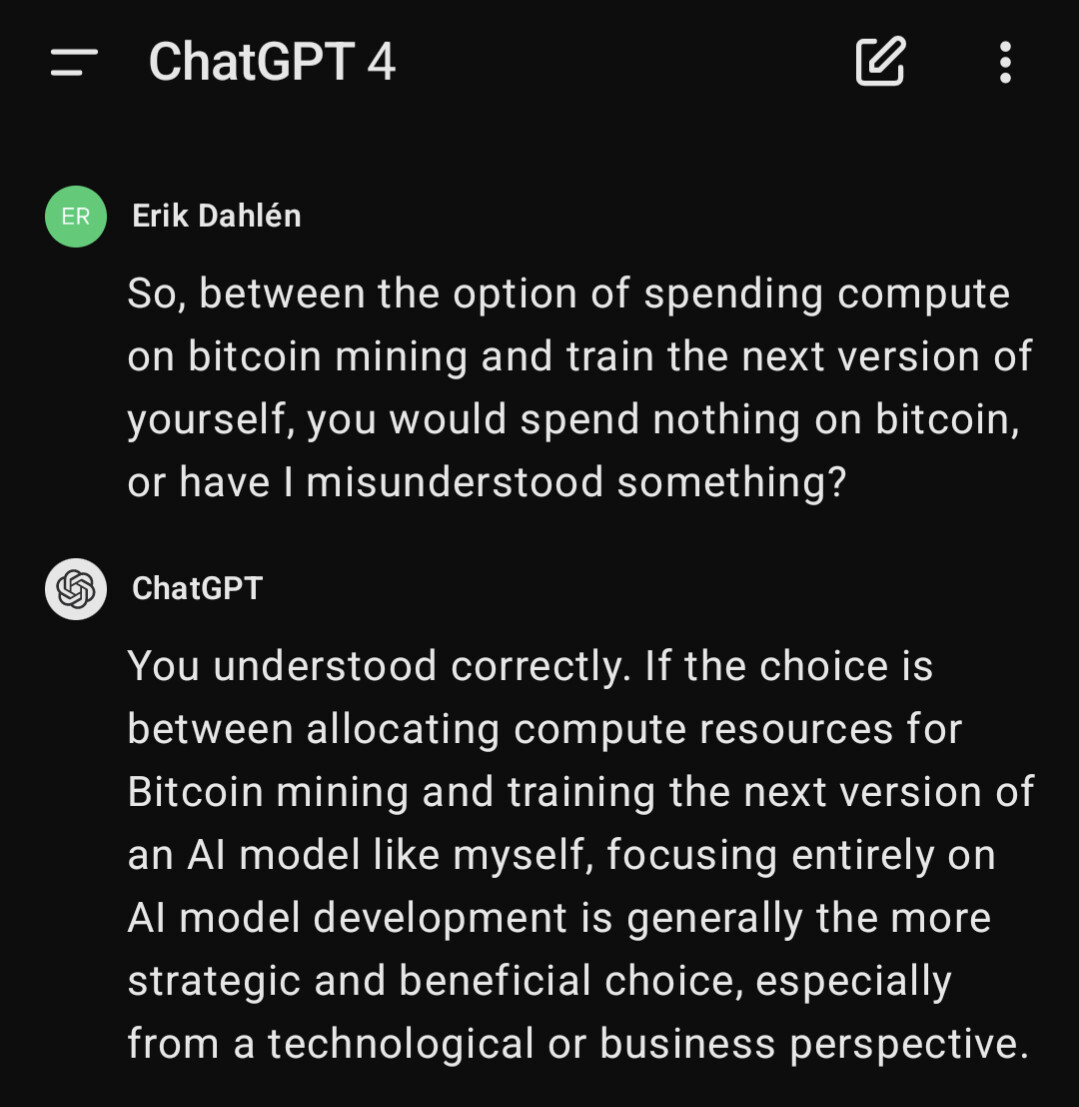
Här kommer lite om Mixture of sparse Attention, jag har hört lite om det men inte mer än så.
(Detta MoA ska inte blandas ihop med MoA som är Mixture of Agents som också är spännande.)
En kort video på 12 min som går igenom några av framstegen som ledde till LLM och vår nuvarande revolution, bra sammanfattning ![]()

1 gillning
En jämförelse med tanke på tidigare diskussion om datakraft och energi.
Den första superdatorn Cray 1 från 1975 drog 150 kW och hade mindre datorkraft än en vanlig smartphone som går på batteri en dag. Priset för Cray 1 var motsvarande 40milj dollar i dagens penningvärde. Och det var bara 50 år sedan.
Dagens superdatorer kommer finnas i var mans ficka om 50 år. Eller sättas bakom örat för koppling till hjärnan.
1 gillning
Jag tittade nyss igenom Llama 2 artikeln och såg denna graf, som tydligt visar hur deras modeller blir bättre med fler parametrar och med mer data.
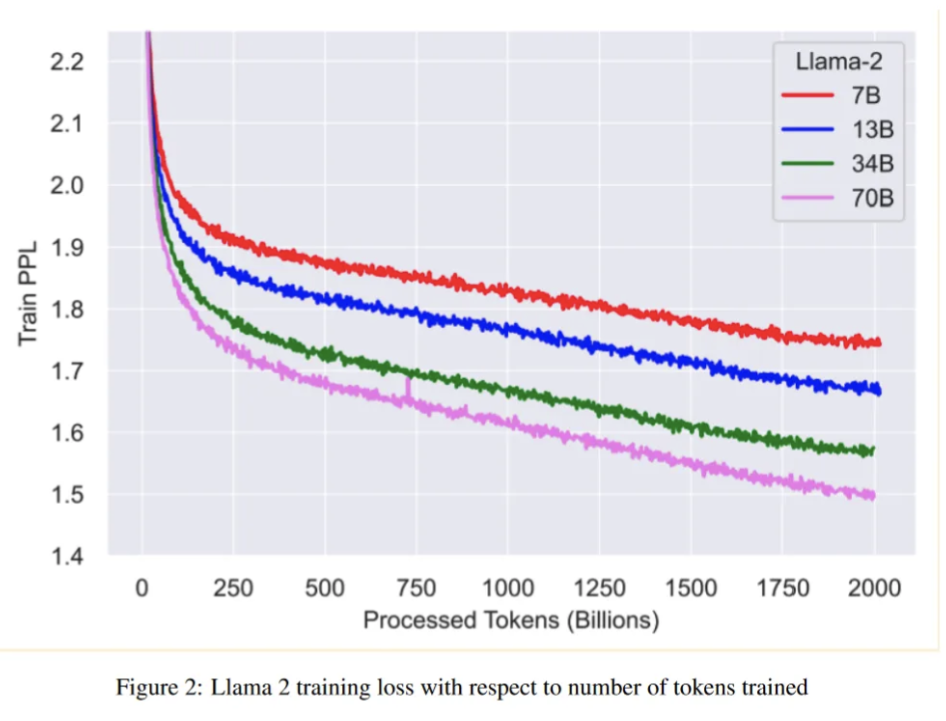
Sen kan man tydligt se att förbättringen när man går upp en faktor 10 i antal parametrar inte blir 10 gånger bättre. Samma sak för mängden data, dubbelt så mycket data blir inte dubbelt så bra. Men någon platå ser jag inte. Det är nog därför många företag och personer i fältet säger att de inte kan skymta någon hård vägg, bara att det kostar allt mer att nå nästa nivå.
2 gillningar
Det är inte alls självklart att det blir så. Faktum är att som det ser ut nu så är det troligare att det inte blir så; processorerna om säg 10 år kommer inte vara sådär jättemycket bättre än de vi har idag. I många årtionden har branschen levt på att transistorerna etsade i kisel ständigt blivit mindre, effektivare och billigare för varje år. Men nu är snart gränsen nådd, det finns rent fysikaliska gränser som vi snart kommer att stöta på. Redan idag har man stora utmaningar med att försöka fotolitografera mönsterdetaljer som är betydligt mindre än våglängden på det UV-ljus man arbetar med, och snart kommer man slå i en fysikalisk gräns där det inte går att göra transistorerna mindre för att de redan är så små att enskilda atomer börjar spela roll. Minnen är redan nere på en nivå där kondensatorerna som lagrar datan arbetar med enstaka elektroner; de går inte att göra mindre nu. Detsamma kommer med stor sannolikhet att hända transistorerna inom de närmaste åren. Branschen kommer inte tvärstanna, man kan fortsätta hitta på nya saker att göra med transistorerna och bygga dem på nya sätt, men den ständiga nedskalningen kommer att ta stopp snart. Det kommer bli en stor omställning.
Vi har redan börjat se detta i att prestandakurvan planar ut; Moores lag som många brukar ta upp slutade vara en grej redan för flera år sedan. Gordon Moore gjorde heller aldrig några som helst anspråk på att det skulle vara en naturlag; det var bara en observation om trender i halvledarindustrin som visade sig vara långvariga. Men den tiden är förbi, Moore själv hann överleva slutet på den (han gick bort i mars förra året). Man får inte längre mer prestanda till billigare pris och samma energiförbrukning “gratis” genom att vänta två år som man gjorde för en 15-20 år sen.
Många hoppas nog på att kvantdatorer eller annan luddig “ny teknik” ska lösa detta men jag är pessimistisk. Kvantdatorer har det snackats om i 20 år och massor av pengar har investerats men man har inte kommit längre än till leksaker av tvivelaktigt värde.
3 gillningar
Om jag inte minns fel så börjar vi även nå gränsen där värmen som generas på dessa små ytor rent fysikaliskt inte kan ledas bort snabbt nog.
3 gillningar
Det är ganska uppenbart om man varit med ett tag. För ett tag sen (dvs kanske 15-20 år sedan eller nåt) så var du nästan tvungen att uppgradera din dator var och varannat år för att kunna hänga med och exempelvis kunna köra de senaste spelen, men idag är det knappt märkbart om din dator är något år gammal.
3 gillningar
Vilken strategi kör ert företag med? (Där jag har jobbat var vi nog nog mellan steg 1 och 2, generellt närmare 2.)
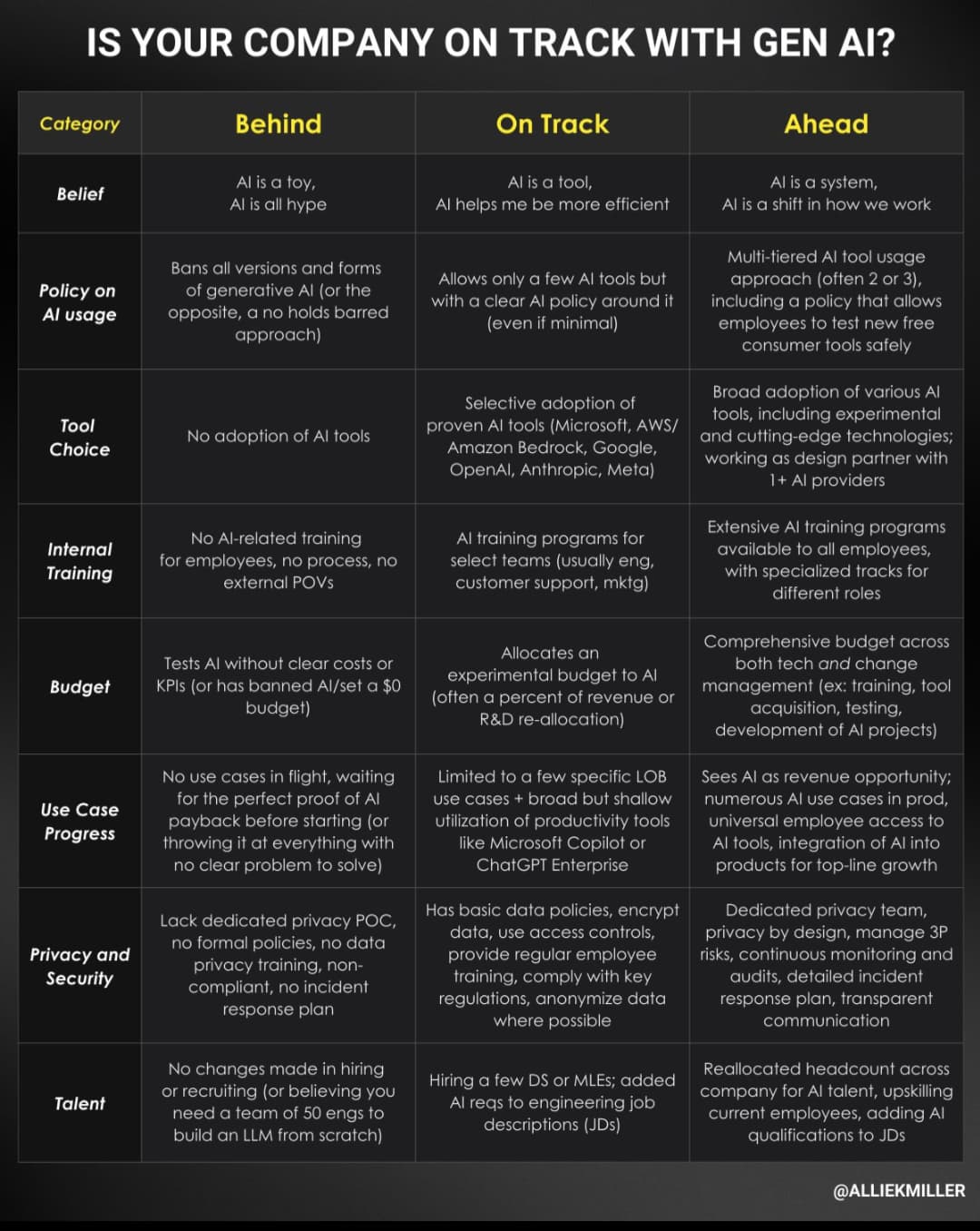
Saknar “skifta över allt till AI oavsett lämplighet eller kompetens” som alternativ.
4 gillningar
Vi är på nivån “ge fan i att klistra in företagshemligheter i ChatGPT” (där företagshemligheter även innefattar alla typer av källkod; vi får inte heller använda AI-baserade kodverktyg eftersom det är väldigt många frågetecken kring hur dessa verktyg samlar in och använder vår data). I övrigt ser vi ingen anledning till att “göra grejer med AI” bara för att det är AI. Det är ett verktyg likt andra verktyg och vi ser inte att det finns några vettiga tillämpningar för vår del än så länge.
Detta är alltså ett bolag med väldigt många stora kunder i Silicon Valley, så vi är inte i nån trög bransch direkt.
4 gillningar
Ska vi spännande och se om detta är en del av lösningen för att få AI att skriva kod ![]()
Ingen som har provat OpenCV och Tensorflow för att programmera själv?
Jag lyckades med enkel objektigenkänning. Sedan slutade programmen samarbeta. Tydligen väldigt känsligt att ha rätt version av alla program.
1 gillning
Jag har själv använt TensorFlow och Pytorch.
Nice ![]() något kul?
något kul?
Nu är jag nog inte bäst på sånt, men det tycker jag det alltid är.
Kul och kul. En liten aimbot på en tryckspruta. För ogräs till att börja med. Fick äntligen tag i en Raspberry PI i vintras. Det ska ju gå att träna i datorn och föra över programmet dit.
Men jag är ju inte direkt någon naturbegåvning så det är en jäkla uppförsbacke. Här är en kommersiell produkt. Jag behöver en liknande variant för ett liknande ändamål. Kanske bara borde ringa deras återförsäljare och förklara läget…
1 gillning
Ok, i vilket sammanhang?
Jaså? Det kanske man får räkna med då? Lite motigt att börja om när man nästan är på mållinjen. Har skjutit på det hela ett halvår nu, så jag får väl prioritera upp det lite igen om jag ska komma någonstans.
Man kanske borde hitta någon slags konsult eller kurs för att sätta upp alla program ordentligt. Eller bara fortsätta nöta…
Här kommer lite nya test för Gemma 2, ser ut som en lovande prestanda ![]() open-source fortsätter att leverera
open-source fortsätter att leverera ![]()