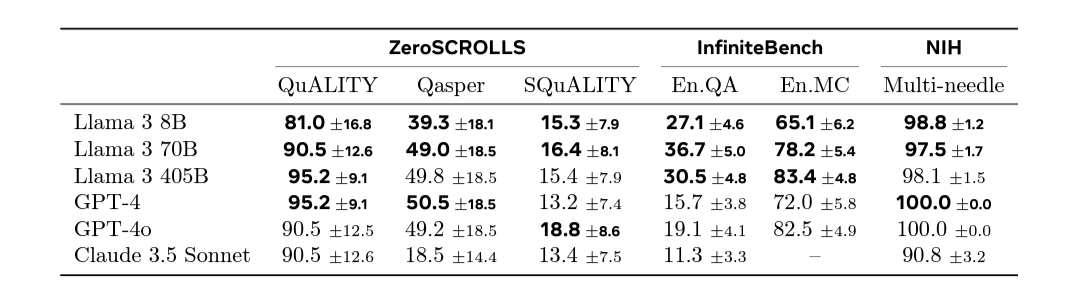
Den tekniska rapporten för Llama 3.1 innehåller många fina saker. Här kan vi se hur bra olika modeller är på att återge fakta från sitt kontextfönster.
En cool detalj är att GPT-4o har 100% på att hitta en bit fakta dom har nog hittat en bra lösning för just detta. När jag själv testar så fungerar det utmärkt:
Om vi kan få modeller som kan återge fakta från dokument med 100% korrekthet så finns det nog en del bra användningsområden. Sedan hade det varit trevligt med betydligt högre siffror på InfinitBench, där modell inte bara ska hitta fakta utan även förstå mer kluriga frågor kring texten/dokumentet.
För mig är Llama 3.1 det största som hänt på ett tag, inte pga prestandan utan för den medföljande tekniska rapporten innehåller många guldkorn.
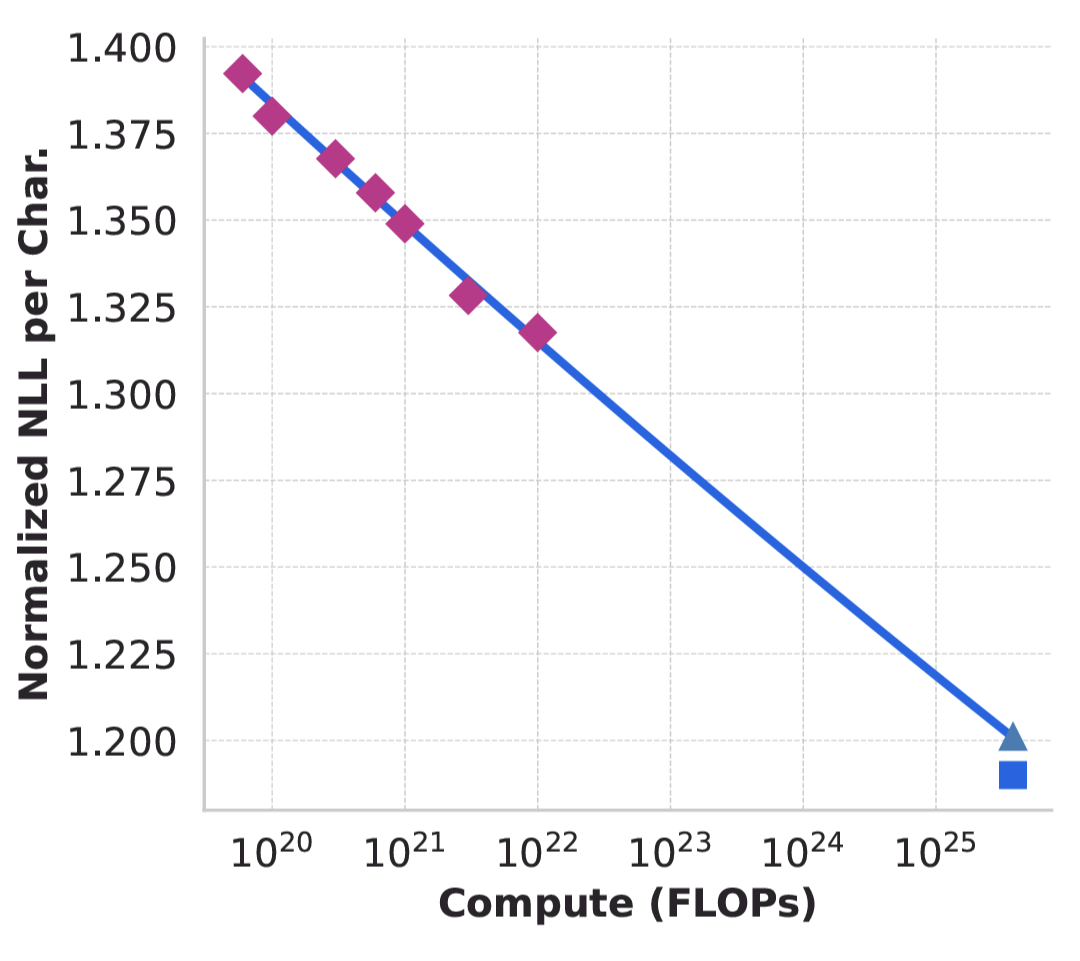
Här är ett fint exempel från rapporten där man dels kan se hur prestandan blir bättre med mer beräkningskraft och dels hur fint det går att extrapolera
Normalized negative log-likelihood of the correct answer on the ARC Challenge benchmark as a function of pre-training FLOPs.
Det är coolt att de kan träna 7 små modeller, plota deras prestanda på ett visst benchmark och sedan dra en trendlinje för att kunna gissa hur bra deras 405B modell kommer bli.
Jag nämnde ett jobb från IBM på 1980-talet.
Där man genererade ett ord i taget och hade en tidigare sekvens av ord som indata.
Dvs det man gjorde var detsamma. Men man hade en försumbar beräkningskraft mot idag, och försumbar träningsdata, och lagrade vikterna lite annorlunda.
Transformerarkitekturen har nog någon påverkan, men lär vara helt försumbar jämfört med datorkraft och träningsdata.
Istället för att lägga mdr på träning ska du träna på en mobiltelefon med neddragen klockfrekvens för att få den beräkningskraft man då förfogade över.
Automatöversättning mellan språk tror jag i sig att de kan bli bra på.
Och så kan vi få en form av “augmented reality” där mindre kompetenta kan få en “förstärkning” så de kan göra mer kvalificerat arbete.
Men att de som investerat massor i “AI” kommer få tillbaka sina stålar är väl tveksamt. Jag tror det blir svårt att få till 0% avkastning. Däremot kommer väl andra profitera i ett senare skede. Det brukar bli så.
Jag vet att det finns flera olika typer av projekt förr som genererade sekvenser av text. Först RNN och sedan LSTM som kom på 90-talet. Enligt mig finns det dock en anledning till att man gick vidare till en ny arkitektur. Bland annat att Transformers är relativt enkel att träna parallellt samt att prestandan var bättre.
Förresten, har du en länk till något som går att ladda ner och testa från den tiden?
Ska jag tolka det som att du tillhör dem som hävdar:
Ja, det har tveklöst skett framsteg vad gäller arkitektur och metoder för snabbare träning.
Dock är de insignifikanta i jämförelse.
Nja, hur tänker du här?
Om du råkar ha en gammal fungerande IBM mainfram från 1980-talet som råkar ha rätt os-version så skulle det ju gå att prova.
Men har du verkligen det?
Det är väl knappt någon som har det och då finns inte mycket mening i att publicera binärer för detta.
Det är ingen som underhåller research-kod och när ett projekt är klart så städas koden bort, för utrymmet behövs för annat.
Minne var dyrt förr.
Skulle inte uttrycka mig så. Men det skulle vara intressant att se hur alla ny finesser levererar på gammal HW och gamla data.
Min gissning är att man inte ser någon skillnad.
En sak att begrunda är att en hel del av finesserna bara är tillämpliga på stora nät och kraftfulla processorer. Alla dessa är värdelösa när man kör på gammal HW, och single-thread.
Jag håller väsentligen med Hkarn i det han skriver.
De här modellerna är användbara även för bildgenerering. Med segmenteringplugin i Stable Diffusion kan man t ex byta mönster på folks kläder, byta prylar som står på en bänk, och liknande. Det är väldigt smidigt att slippa maska ut saker själv.
Det är mer troligt att de här verktygen blir en förstärkning för den minst kompetenta halvan av befolkningen. Inte den övre.
Men detta innebär att den mindre kompetenta halvan då kan göra ett jobb av högre värde. (ja, det här gäller då de som gör ett jobb där dom kan få hjälp av något verktyg. Gäller väl inte alla arbetsuppgifter).
På så vis höjs värdeskapandet i genomsnitt, och en förhöjd BNP/Capita kan nås. (Sedan kan man naturligtvis fråga sig om det kommer bli någon avkastning att tala om för de som investerat. Det är väl tveksamt. Det får nog ses som en form av välgörenhet).
Detta tangerar augmented reality som också kan bli en förstärkning för en del personer, som då kan leverera att större värde.
AR är totalt stendött, Zuckerberg har verkligen gjort sitt bästa för att ta kål på hela idén. Meta har förlorat nånstans i storleksordningen 50 miljarder dollar på några år genom att lalla runt och tramsa med idiotiska produkter som ingen utom Zuckerberg själv tror på. Det finns verkliga tillämpningar för AR, men det är extremt nischat och knappast affärskritiskt för någon. Det är en rolig gimmick, men inte mycket mer än så. Apples Vision Pro totalfloppade ju också och även dataspelsbranschen håller på att ge upp VR (Sony verkar totalt skita i PSVR2 nu) så det är inte bara Meta som totalt misslyckats med detta. Folk har hajpat VR/AR sen 90-talet och sagt att om fem år kommer vi alla gå runt med headset hela tiden, men trots att grafiken blivit otroligt mycket bättre har vi fortfarande exakt samma problem som för 20 år sen: man blir åksjuk och användargränssnitten är helt hopplösa. Här är en artikel från NASA Ames Research Center från 2004 som lika gärna kunde ha publicerats igår; problemen är exakt desamma nu som då.