Ett litet steg för att göra bättre bedömningar av benchmarks ![]()
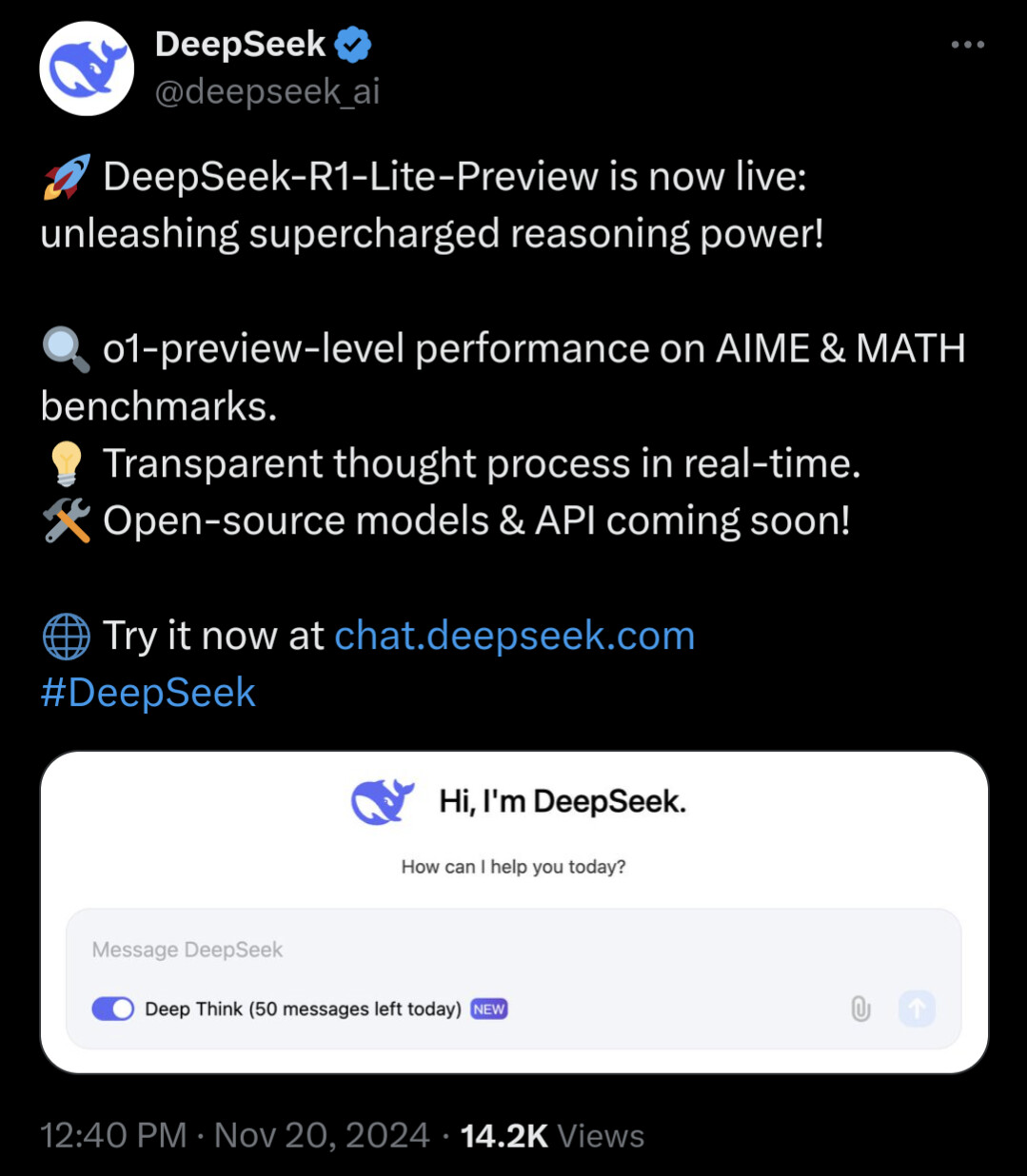
2 gillningar
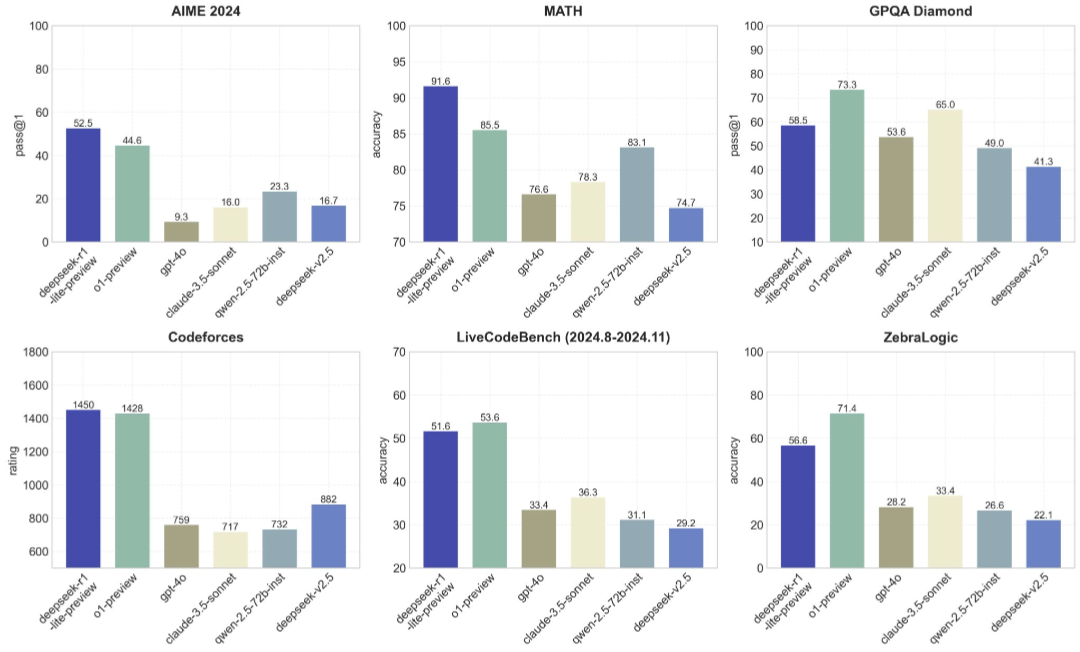
Frågan är om o1 kan lösa frågor den aldrig sett tidigare, eller om alla frågor lärare kan hitta på redan finns på internet någonstans ![]()
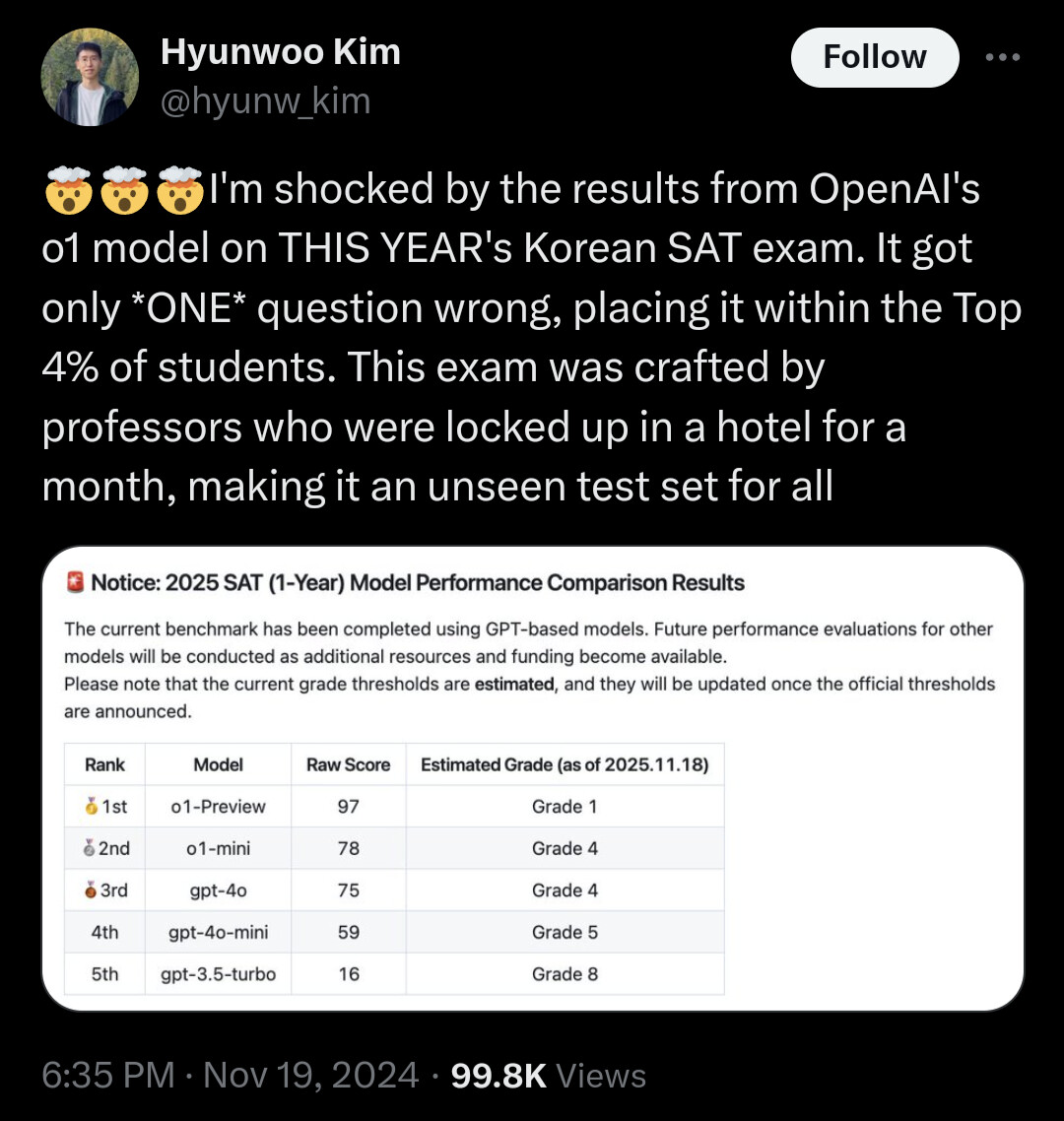
Länk:
2 gillningar
Det korrekta sättet att testa är att endast använda en slumpmässigt utvald del av training data som modellen ej får tillgång till under träning. Sedan göra samma sak många gånger.
Sånna där test får man ta med en nypa salt ![]() men det säger kanske någonting ändå.
men det säger kanske någonting ändå.
1 gillning
Någon har testat ifall människor kan se om AI har skapat en bild ![]()
1 gillning
Ännu en kort video på en robot ![]()
Väldigt coolt grej ![]()
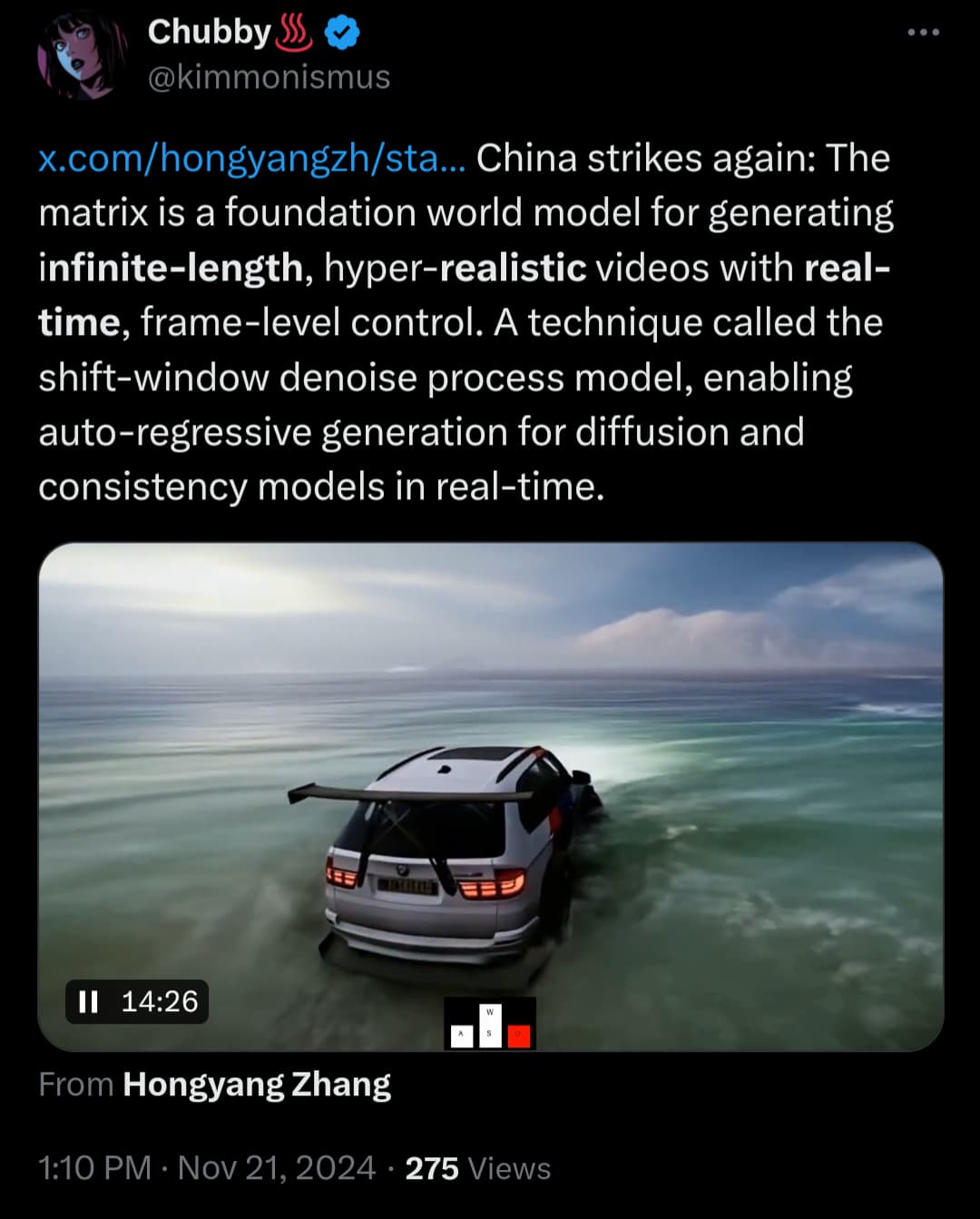
(Någon behöver nog berätta för honom att det nog inte är oändligt på riktigt.)
Länk:
1 gillning
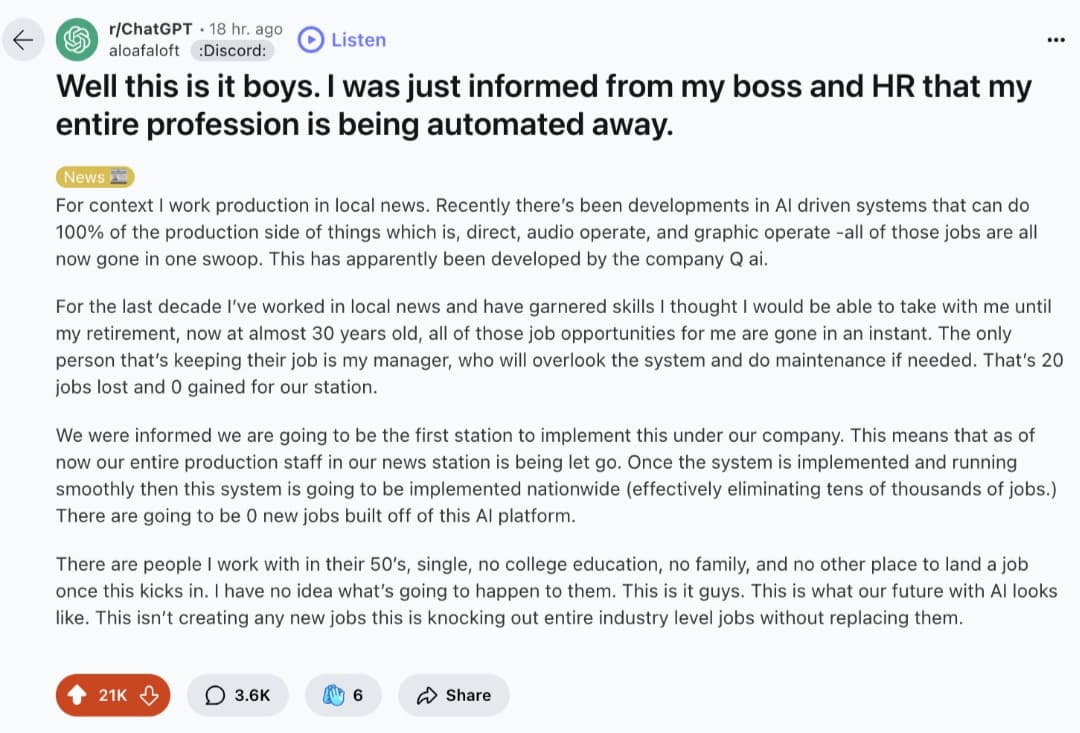
Det finns ett litet problem med modeller från Kina ![]() (detta är r1 från DeepSeek, som ska konkurrera med OpenAI.)
(detta är r1 från DeepSeek, som ska konkurrera med OpenAI.)
Sen kan man alltid fråga sig om det finns saker som amerikanska bolag filtrerar bort som vi i EU hade haft en annan syn på.
Nu vill Google att AI/Transformers ska lösa kvantdatorer åt oss ![]()

Det finns dock inget som säger att man inte kan lagra mer en bit i varje partikel. Man kan säkert använda en mängd states för att representera olika bitar, som state, position, vektor och annat. Universum i sig innehåller mer information än den där siffran—alltså borde universum kunna representera mer information än den?
Om någon är intresserad av nya arkitekturer inom AI ![]()
Spännande att se hur mycket bättre modeller blivit på att hitta information i dess kontextfönster ![]()
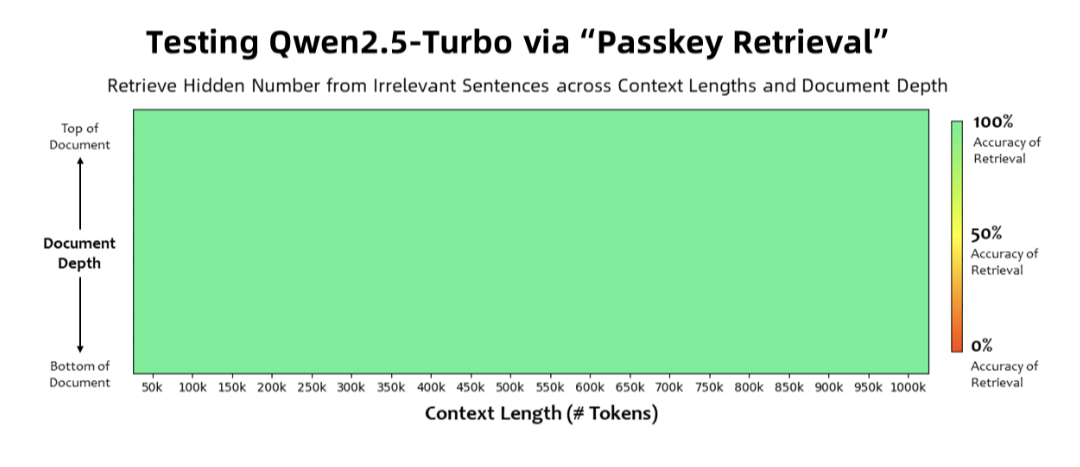
Källa:
2 gillningar
AI video har en liten bit kvar, men utvecklingen är spännande ![]()
Här kommer något som GPT-4o har byggt i Minecraft ![]()
OpenAI sprider hype om att vi inte nått någon vägg ![]()
1 gillning
Lite oklart vad man vill uttrycka med ordet “vägg”. Det är möjligt att det inte går att skala upp en språk modell till att lösa avancerade logiska problem. Men det finns en hel del vägar att gå runt just den väggen ![]() det finns väldigt bra system för att lösa avancerade logiska problem.
det finns väldigt bra system för att lösa avancerade logiska problem.
1 gillning
Bra fråga, det borde nog någon som tror att vi nått väggen svara på.
Själv tror jag att att det är praktiskt för skeptikerna att använda diffusa ord när man efteråt vill kunna säga att man hade rätt. Genom att säga att nästa generations modeller har nått en vägg kan man efteråt definiera det. Det är ofta så att allt inte blir bättre men några saker blir det. (Ryktet för Gemini 2 är att den är bättre på språk men inte programmering, och det gör en del besvikna men kommer nog ändå göra den mer användbar till att sammanfatta dokument och översätta.)
Ibland behöver man påminnas sig om hur det såg ut tidigare, allt blev inte bättre hela tiden. (Hoppet mellan GPT-3.5 och GPT-4, jag ser 8 staplar utan förbättring.)
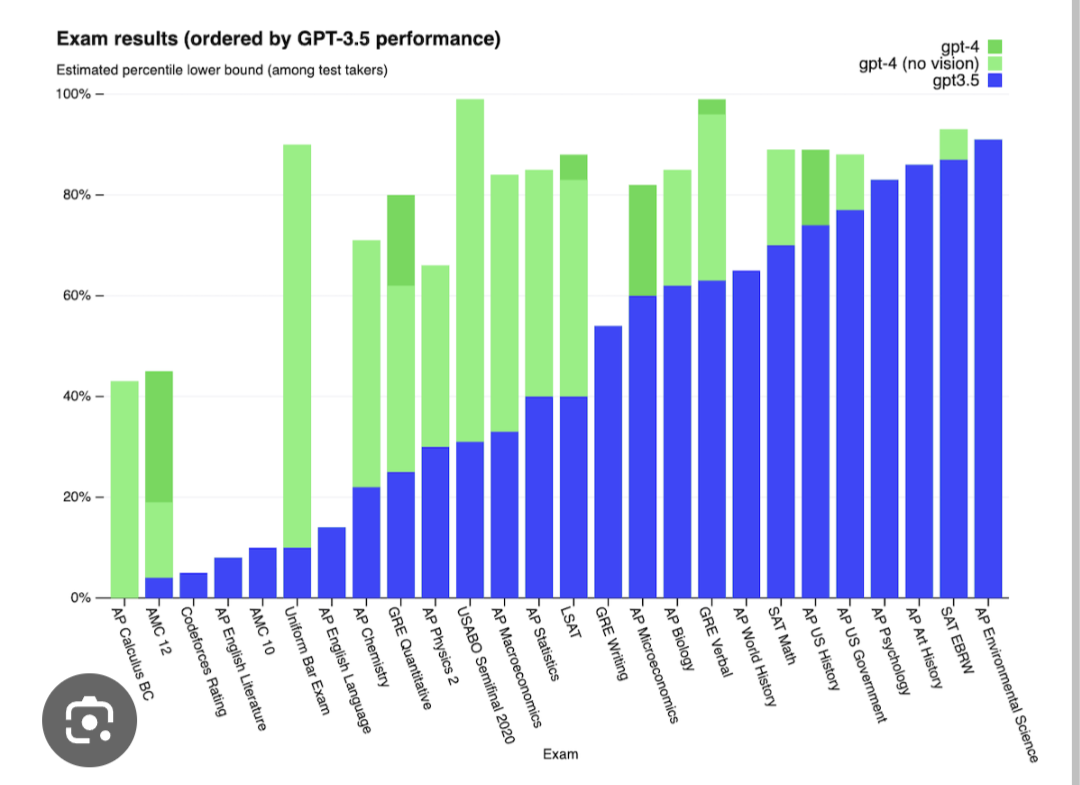
1 gillning