Intressant fortsättning i sagan om upphovsrätten ![]()
Här görs stora påståenden:
Like AlphaGo’s Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation.
Läs artikeln här:
1 gillning
Intressant diskussion om estimat! Jag hade inte haft något emot om det bröts ut till egen tråd.
Där jag jobbar har vi gått genom följande resa de senaste åren:
- Alla i teamet estimerade genom att föreslå en poäng för uppgiften. Genomsnittet togs. Om någon avvek mycket blev det diskussion.
- Vi ersatte poäng med Small/Medium/Large eftersom vi insåg att det är meningslöst att diskutera om det är “8” eller “13”. Fortfarande blinda bud (alla visar en lapp samtidigt).
- Nu gör vi så att den som skriver uppgiftsbeskrivningen sätter en poäng (S/M/L). Endast om någon har problem med detta estimat tas det upp för diskussion.
I praktiken betyder nivåerna:
S: vi vet exakt hur man ska göra och det går snabbt.
M: som S, fast det är lite mer att göra.
L: innehåller osäkerhetsmoment, kan ta några dagar eller mycket längre.
2 gillningar
Ja, jag har pingat mod och bett om splitt. ![]() De lär ta det nästa gång de betar av kön.
De lär ta det nästa gång de betar av kön.
2 gillningar
Mitt bidrag till estimat är att jag tycker det är svårt. Att ge exakta tider blir bara fel, men någonstans bör man ha en ide om när något eventuellt kan bli klart.
Jag upplever även att man behöver ha koll på hur lång tid något ungefär kan ta då vi har krav på någon typ av ROI. En ny funktion som sparar teknikerna 2 timmar i veckan per person, så bör vi veta ungefär hur svårt det är att få till, för är det för dyrt så blir det kanske billigare att vara låta den göra det manuellt några år till.
Som på min arbetsplats nu, så frågar vi oss vilka nya funktioner och vilka kända buggar/begränsningar är rimligt att hinna med till vår release i september och vad får vänta till den i slutet av året?
För att nå en kompromiss så kör vi med komplexitetspoäng. Fördelen är att vi inte lovar när det blir klart, men det är ändå möjligt att ha ett hum om vad som är svårt och vad som är enkelt.
Än så länge fungerar det även bra för de som betalar budgeten ![]()
Nu när GPT-5 förhoppningsvis börjar närma sig, så ska det bli kul att se vad nästa nivå består av. Jag förväntar mig ett delta över o3 som är lika stort som det från o1 till o3. Större än det blir jag positivt överraskad, under blir jag besviken.
Självklart har jag börjat förbereda mina egna tester, i mitt nuvarande Brio-benchmark ![]()
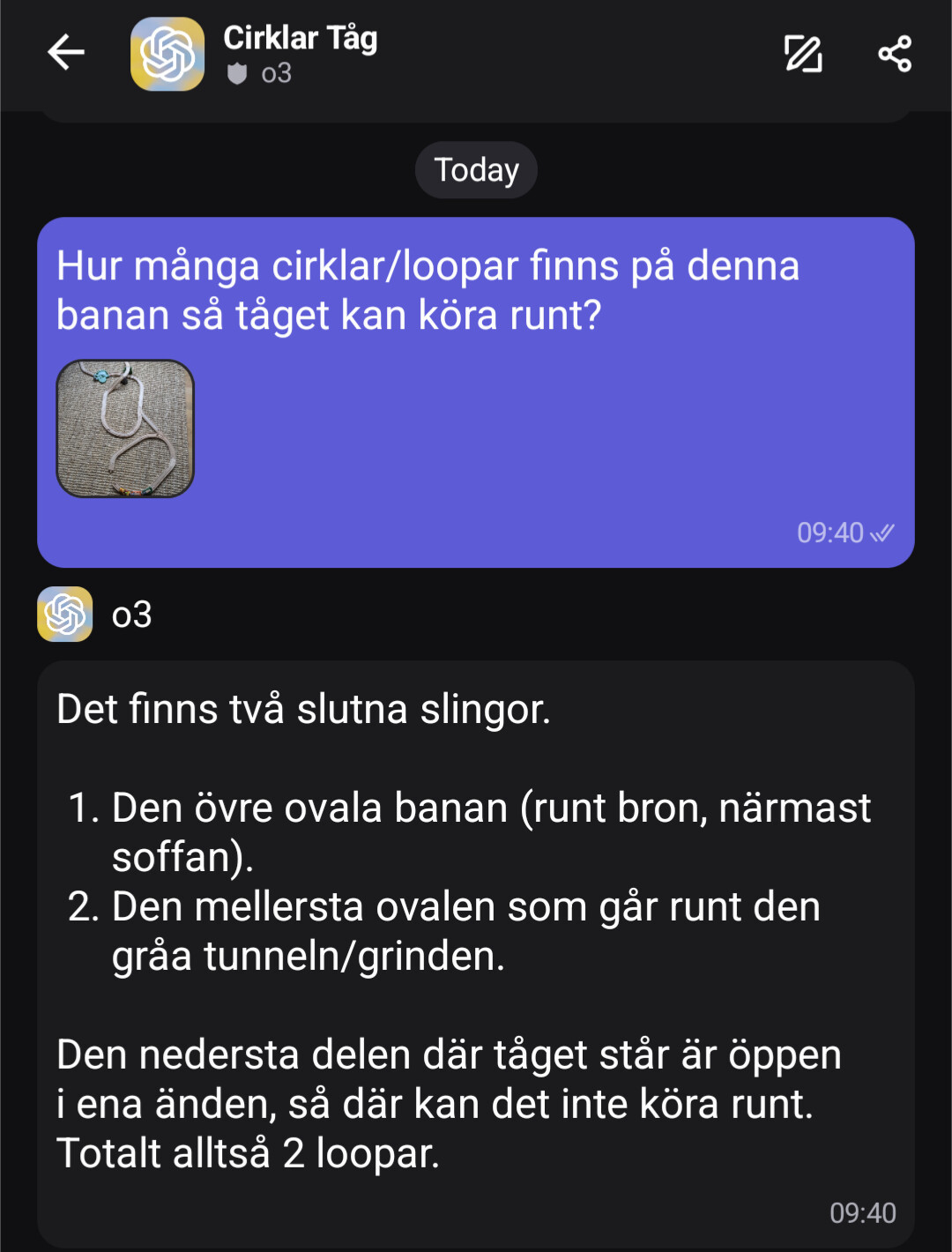
1 gillning
Ja, det är vad jag sett ingen som egentligen argumenterar mot behovet—det handlar mest om en klarsynthet över om det är görbart eller om det är en önskedröm.
Man kan stå och vilja någonting, korsa sinafingrar, ta i och önska ända nere från tårna, men det gör det inte nödvändigtvis möjligt ![]()
Det som nämndes ovan med att den som skriver en issue markerar med liten/mellan/stor är t ex användbart som diskussionsmaterial. Jag skulle dock snarare kört på nivåerna: lagom (S), tillräckligt liten (M), och för stor (L). ![]()
Håller med, i allt du skriver. Ca 10x är en vanlig faktor, jag har kanske inte sett 100x men kan se att det kan bli så. I det fallet är ju arbetet med estimat extra värdefullt, eftersom det gör det tydligt för beslutsfattare att osäkerheten är så pass hög.
Du argumenterar alltså för att ett tärningskast mellan 0 och oändligheten är ett lika värdefullt underlag som estimatdelen i en väl genomarbetad förstudie? Bara så jag förstår rätt. Spontant låter det som extrem inkompetens.
De andra aspekterna som du tar upp håller jag med om, men de hör inte till frågan. Eftersom vi diskuterar huruvida just estimatet bidrar med ett värde. Övriga aspekter kommer alltid att finnas där oavsett. Men det jag menar är att det blir mycket svårare att ta ett beslut utan att ha ett hum om totalkostnaden. “Har vi som bolag ens kassaflöde för att lansera vår produkt i USA?” -“Nej vi kollade aldrig det för det var en kille här som inte tror på estimat.”
För att inte bara prata om när/om AI tar över jobben inom programmering, någon som har en känsla för om detta är rimligt? Har relativt dålig koll på juridik och vad jurister gör på företag ![]()
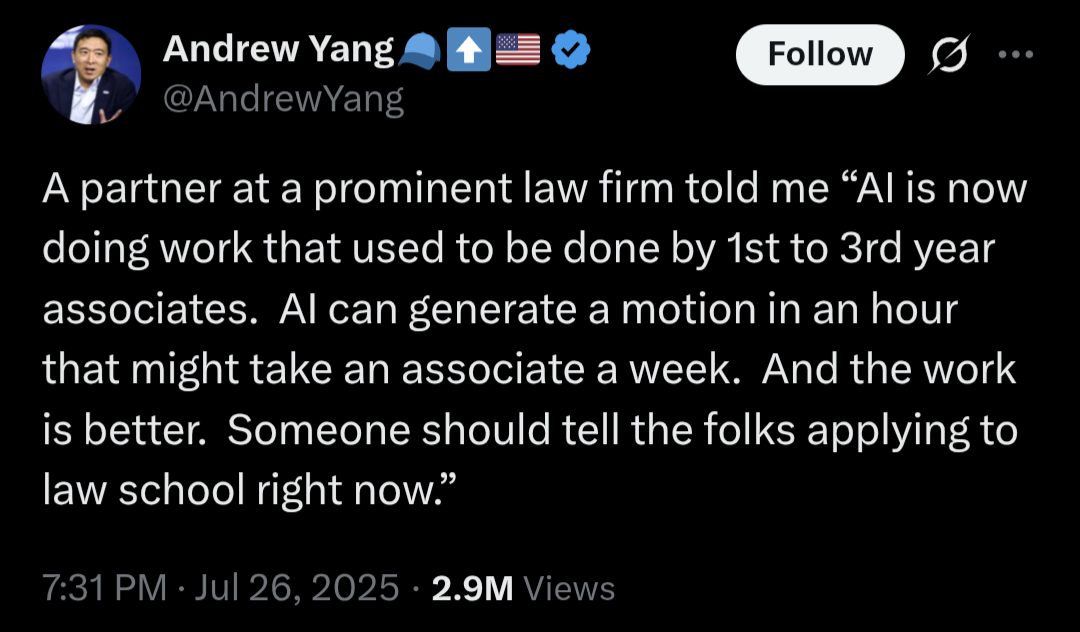
The Verge har skrivit en hel del om advokater som har fått böter och hamnat i annat trubbel för att de använt generativ AI och då hänvisat till olika fall som inte finns, helt hallucinerade. Man kan bli avstängd för denna typ av fel i dokument inlämnade till domstol, och dömd till olika typer av straff.
Så ja, det känns ur den contexten rimligt.
Jag har inte läst nedan artikel av The Verge ännu, men den är recent och summerar hela grejen, om jag inte helt misstar mig:
1 gillning
Jag skummar lite här ibland. Postar den mest för om någon letar sajter som inte är ren dagspress-nivå:
1 gillning
Det finns en färsk artikel om detta på svenska också, på sajten Realtid.
2 gillningar
Så det beter sig ungefär som för programmering då: du kan generera text, men den måste granskas.
2 gillningar
Frågan är om detta är ett övergående problem, eller om det kommer bestå. Det går ju att tänka sig system som dubbelkollar sina påståenden efteråt, men inte säkert om det kommer räcka.
Är det inte lite det de resonerande modellerna gör? Kör igen och kollar om det blev rätt?
Resonerande modeller utökar modellens kontext genom att simulera “thinking tokens” och såvitt jag vet även slänga in ett par “But wait” eller “What if” för att få den att expandera vidare.
Iden är att man har mer relevanta tokens i kontexten för attention mekanismen att “bygga på” när svaret skall genereras. Det är inget speciellt med dessa tokens egentligen och du skulle få samma resultat om en människa skrev in … manuellt istället.
2 gillningar
Det är min bild också, dessa resoneringsmodeller “tänker längre” och delar upp det i steg, typ läger själv till “solve this step by step”.
Om jag har förstått det hela rätt så tänker jag ett system mer likt AlphaEvolve. Där en modell först genererar flera svar, för att en annan modell sedan granskar dem, för att sedan förbättra de bästa svaren och sedan lämna ett slutligt förslag till användaren.
Som jag har tolkat det så är det lite så o3-pro och Grok 4 heavy fungerar. Dock har det inte känns som att det är värt 200+ dollar i månaden. (Dessa genererar nog 4 förslag i steg 1, till skillnad från AlphaEvolve och AlphaCode som genererar 100+ om jag kommer ihåg det rätt.)
2 gillningar
Jag tänkte på research-grejen som finns på tex OpenAI där den resonerar och söker och resonerar igen i flera steg.
1 gillning
Aha, jag tänker mig också att Deep Research borde hjälpa en hel del. Har dock inte koll på om de har använts vid några av dessa fallen. Hade inte varit förvånad om de använt någon billigare modell, typ GPT-4o. (Den är väl fortfarande standard i ChatGPT.)
1 gillning
För det jag vill använda den till så tror jag dess för lilla context-fönster är det som sabbar grejen. Även Googles större fönster är alldeles för litet. Man får en viss klass av problem där den tappar bort grejer i större material.