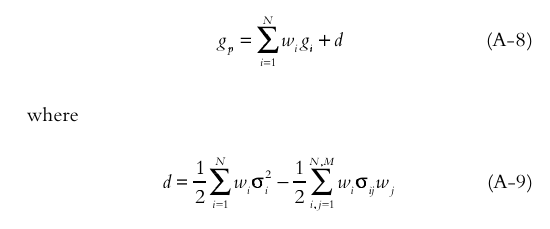Detta var ett intressant problem. Har du någon bra referens med härledning av RP med hävstång? När jag pillar lite med detta numeriskt så tycker jag mig se att statistiken blir växande icke(log-)normal för stora hävstänger vilket gör jag blir misstänksam på att det finns normalitetsantaganden eller Taylorutvecklingar, som gör att det inte riktigt håller för stora hävstänger.
För att illustrera de numeriska resultaten så är vektorn ret slutvärde efter 10 år på en portfölj som börjar med 1 krona, två negativt korrelerade tillgångar med väntvärde 0 i avkastning
Utan hävstång så är slutvärden och cagr rimliga, väntvärden ungefär samma som median.
Med hävstång på 10 blir fördelningen på slutvärden på portföljen väldigt skev, och väntvärdet på cagr skiljer sig kraftigt från cagr baserat på väntvärde av slutvärde
Portföljerna kommer naturligtvis att utvecklas exakt likadant i absoluta kronor, och det går inte att se skillnad på dom “utifrån”. Nyckeln ligger i att det enda vi bryr oss om är utvecklingen och risken gentemot eget kapital. När portföljerna har ökat med 10.000kr så har den obelånade haft en avkastning på 1% och den belånade på 2%.
Jag tror att ordet “ombalanseringspremie” leder tankarna (fullt förståeligt) lite fel. Den största och viktigaste mekanismen är minskad volatility drag. Den förekommer två gånger i uträkningen av CAGR: dels dras den bort i uträkningen av geometrisk avkastning och samma gäller i formeln för ombalanseringspremie.
Med en (teoretiskt) perfekt diversifierad portfölj så kan du med hjälp av hävstång pressa upp tillgångarnas riskpremier utan att portföljens volatility drag ökar i samma uträckning. Når man denna punkt så kan man teoretiskt belåna portföljen hur mycket som helst (om vi bortser från att räntan styrs av belåningsgrad) utan att sänka den riskjusterade avkastningen. Med ökad hävstång får vi en ökande premie gentemot eget kapital.
Hmm, jag ska se om jag hittar det. Jag har för mig att jag fick kolla på flera olika källor och kasta om/härleda och landade varje gång i samma formel.
Två kontrollfrågor till för att hjälpa mig att förstå:
Jag har en portfölj bestående av 100 % S&P 500 likviktat index. Eftersom fonden håller de 500 företagen likviktade så måste den regelbundet ombalanseras och borde därmed erhålla en premie (eller minska volatilitetsförlusterna, om du föredrar). Innehaven är såklart rejält korrelerade, men inte perfekt, så premien torde bli större än noll. Om jag lägger hävstång på denna portfölj till en kostnad lika med riskfria räntan, ökar jag dess Sharpe-kvot?
Jag har en allvädersportfölj. Jag ska nu köpa lägenhet och genom min svåger som jobbar på bank lyckas jag få en ränta på bolånet som är lika med den riskfria räntan. Har jag nu ökat Sharpe-kvoten på min portfölj?
Om jag har två tillgångar och ombalanserar mellan dem så ökar premien med kvadraten på volatiliteten, eftersom de två tillgångarnas volla multipliceras. Om jag har tre tillgångar, ökar då premien med kuben på volatiliteten?
Nej, den ökar inte, men teoretiskt så kan man tänka sig att sänkningen av sharpekvoten bromsas något, men troligtvis så extremt lite att det inte är mätbart (pga av att korrelationerna inom indexet är väldigt nära 1). Jag körde en simulering med 500 aktier med slumpmässig korrelation mellan 0.95 och 1.0 och noll i räntepremie. Vid hävstång = 1x blev ombalanseringspremien 0.03% och Sharpekvot 0.4, vid hävstång = 1.5x blev ombalanseringspremien 0.06% och Sharpekvot 0.36.
Jag antar att du ska köpa lägenheten för dom pengarna och inte investera dom i portföljen? Isåfall påverkas inte portföljen.
Om du kollar på formeln för ombalanseringspremien (RP) så ser du att man summerar de viktade volatiliteterna och sedan tar kvadraten på summan, så nej.
Nej, med en diversifierad portfölj så växer första termen i RP fortare än volatilitetsförlusten.
@CarlJohan Den här har bra sammanfattade formler i slutet, dock utan hävstång. Man bör komma fram till samma sak om man bara multiplicerar riskpremie och volatilitet för varje enskild tillgång med \lambda
Vänta, nu minskar Sharpe-kvoten istället? Om ombalanseringspremien är det som ökar den, hur kommer det sig att den minskar? Normalt så är ju Sharpe-kvoten oförändrad vid hävstång med kostnad lika med riskfria räntan. Får vi en ombalanseringspremie på 0,06 % så borde det driva upp Sharpe-kvoten. (Jag tror ju inte på detta, men enligt argumentet så långt.) Vad är det för mekanism som gör att den minskar?
För att få en annan Sharpe-kvot på den här (högre eller lägre) måste jag ju göra beräkningen på något speciellt sätt. Om jag bara tar avkastning minus riskfri ränta och delar med volatiliteten (vilket är definitionen av Sharpe-kvot) så kommer jag ju att få precis samma resultat med och utan hävstång. Fondens redovisade avkastning och volatilitet är ju desamma oavsett hävstången, och skalar därmed lika mycket när hävstång appliceras.
Jag tycker helt enkelt att resultaten man får när man räknar på det sättet @Zino och @RobertK gör ger orimliga resultat, och då säger min ingengörsinstinkt att det är fel i beräkningen.
Jag är fortfarande öppen för ett exempel. Men jag är ju på strandsemester idag och borde verkligen inte hålla på med detta, och de har säkert också bättre saker för sig egentligen. Men jag finner diskussionen intressant och har svårt att släppa den.
Stämmer det att du tagit dessa uttryck, och sedan applicerat hävstång genom att byta ut \mu mot \lambda\mu och \sigma mot \lambda \sigma? Om så är fallet så ligger nog problemet där. Modellen bygger på lognormal geometrisk periodisk avkastning r_k, dvs \log (1+r_k) \sim N(\mu,\sigma). Om du ersatt på det sättet säger du att \log (1+\lambda r_k) \sim N(\lambda \mu,\lambda \sigma) vilket inte är fallet.
När jag tänker mer på det, som amatörstatistiker, så känns det som att det finns en djupare problematik här som gör det svårare. En lognormal modell bygger ju på man låter daglig utveckling vara r_k = e^{z_k}-1 där z_k är normal. Detta betyder att tillgångens utveckling kan vara -1 (dvs 100% förlust) och obegränsad uppåt. Dvs det är en trevlig modell för att få rätt domän. Om man nu stoppar in en hävstång på detta så blir daglig utveckling \lambda(e^{z_k}-1). Problemet är att denna kan bli mindre än -1 så väntvärdet \log(1+\lambda r_k) måste ersättas med väntvärdet av \log(\max(0,1+\lambda r_k)) vilket blir -\infty om jag inte tänker fel.
Eftersom det är en ex-ante (teoretisk) uträkning av Sharpekvoten, alltså inte efterhand baserat på historiskt data, så är det geometrisk avkastning (CAGR) som är relevant att använda i täljaren. Geometrisk avkastning minskar med ökad volatilitet pga volatility drag.
Jag kan inte säga faktiskt utan att grotta ner mig (igen), men som jag skrev tidigare så tittade jag på många olika källor och kom fram till samma formel fast i olika form. Det är väldigt välkommet om du lyckas härleda/verifiera (eller förkasta) formeln.
Det är formel A-9 som identifieras ombalanseringspremie i artikeln och det ser mycket riktigt ut som den formel som jag har lagt hävstång på. \sigma_i multiplicerat med \lambda i första termen, samma är gjort för portföljens varians i andra termen. Det borde vara rätt att skala upp volatiliteterna där också kan jag tycka?
Equation (A-8) expresses the portfolio growth rate as the sum of the individual asset growth rates plus the premium d derived from diversification and rebalancing. This value is positive for correlations less than one, implying that the benefit of rebalancing to fixed weights is positive. The first term of d is the weighted sum of the component asset variances, and the second is the portfolio variance. An increase in asset volatility increases the first term (increases growth potential from rebalancing) but also increases portfolio variance (decreases growth). The amount by which the second term increases relative to the first largely depends on the correlation among the assets.
Den underliggande modellen som används för tillgångarnas prisutveckling r_k är en lognormal model, dvs \mu och \sigma antas modellera tillgången väl enligt \log(1+r_k) \sim N(\mu,\sigma). Detta säger alltså att distributionen på r_k har ett visst utseende med r_k = e^{z_k}-1 för normalfördelat z_k. Om man nu investerar med hävstång, så ska utvecklingen skalas. Det är dock inte det som sker i din modell där du ersatt \mu och \sigma med \lambda\mu och \lambda \sigma och alltså implicit säger att du investerar i en ny tillgång som beskrivs av en lognormal modell med dessa parametrar. Problemet är att denna distribution ser helt annorlunda ut, dvs när du ändrar \lambda ändrar du prisutvecklingens distribution kraftigt.
Här är ett numeriskt exempel (MATLAB men lätt att ändra till lämpligt språk)
clf
mu = 0;
s = 0.1;
z0 = mu + s*randn(1,10000000);
r0 = exp(z0)-1;
h = histogram(r0, 'Normalization', 'pdf', 'DisplayStyle', 'stairs', 'EdgeColor', 'b');
z1 = 10*mu + 10*s*randn(1,1000000);
r1 = exp(z1)-1;
hold on
h = histogram(r1, 'Normalization', 'pdf', 'DisplayStyle', 'stairs', 'EdgeColor', 'r');
legend('\sigma = 0.1','\sigma = 10*0.1')
axis([-4 6 0 4])
Den underliggande tillgången har alltså ett utfallsrum där mesta massan ligger mellan -0.3 och 0.3 (men teoretiskt mellan -1 och oändligheten), men utfallsrummet för den tänkta 10x hävstångsinvesteringen har inte ett utfallsrum mellan -3 och 3, utan har kapat en negativ svans som drar utveckling till 0 och kraftigt ökat de positiva utfallen. Med andra ord, en analys baserat på denna distribution är inte en analys av den urpsprungliga tillgången med hävstång utan något helt annat.
Vid närmare koll här, varför definierar du CAGR som r_g + RP? Den balanserande portföljen har aritmetrisk avkastning r_a = w^T\mu, och geometrisk avkastning r_g = w^T\mu-\frac{1}{2}w^T\Sigma w. Den beräknade premien RP är väl bara en siffra på hur mycket volatilitetsförlusten har minskat jämfört med att man inte hade balanserat.
Hmm, du kan ha rätt. Att formeln egentligen isolerar hur stor del av den lägre volatilitetsförslusten som kan tillskrivas ombalansering/diversifiering.
Ja, vad jag kanske se har du tittat på ekv (2) där man lägger på premien men missat att man lägger det på en term som definierats som w^T\mu - \frac{1}{2}w^Tdiag(S)w istället för w^T\mu - \frac{1}{2}w^T Sw eftersom de vill skriva w^T\mu - \frac{1}{2}w^T Sw som w^T\mu - \frac{1}{2}w^Tdiag(S)w + \frac{1}{2}w^T(diag(S)-S)w för att tydliggöra enskilda tillgångars volatilitetsdrag vs termer som tar in korrelationer
Om jag har en tillgång i portföljen så är Sharpe-kvoten oförändrad vid hävstång till kostnad av riskfria räntan, enligt min demonstration ovan som du och @zino sagt stämmer för enskilda tillgångar, men inte för flera tillgångsslag.
Om jag har två relativt starkt korrelerade tillgångar så minskar istället Sharpe-kvoten med hävstången.
Om tillgångarna är relativt okorrelerade så ökar istället Sharpe-kvoten.
I enlighet med vad du sagt ovan så gäller detta även inom fonder som jag håller i ett konto med värdepapperslån (eftersom Sharpe-kvoten inte var konstant när mitt enda innehåll var en enskild likaviktad S&P500-fond).
Med detta tolkar jag det som att eftersom en fond innehåller flera olika tillgångar så gäller inte den vanliga formeln för Sharpe-kvot om man äger mer än en (1) aktie. Det känns inte som att detta är hur man vanligtvis talar om Sharpe-kvot.
Ja, med nollränta så påverkas Sharpekvoten bara av den aritmetiska riskpremien och standardavvikelsen för portföljen/tillgången.
Hävstång blir mer lämpligt ju högre Sharpekvot du har på grundinvesteringen, dvs en portfölj eller fond som har högre/liknande riskpremie och/eller lägre standardavvikelse än en globalfond är bättre.
Jag har tänkt att den effektiva marknaden gör att den marknadsvikade globalfonden (inklusive emerging markets, small cap etc.) ger den lägsta möjliga shapekvoten, alla fall innanför tillgångslaget