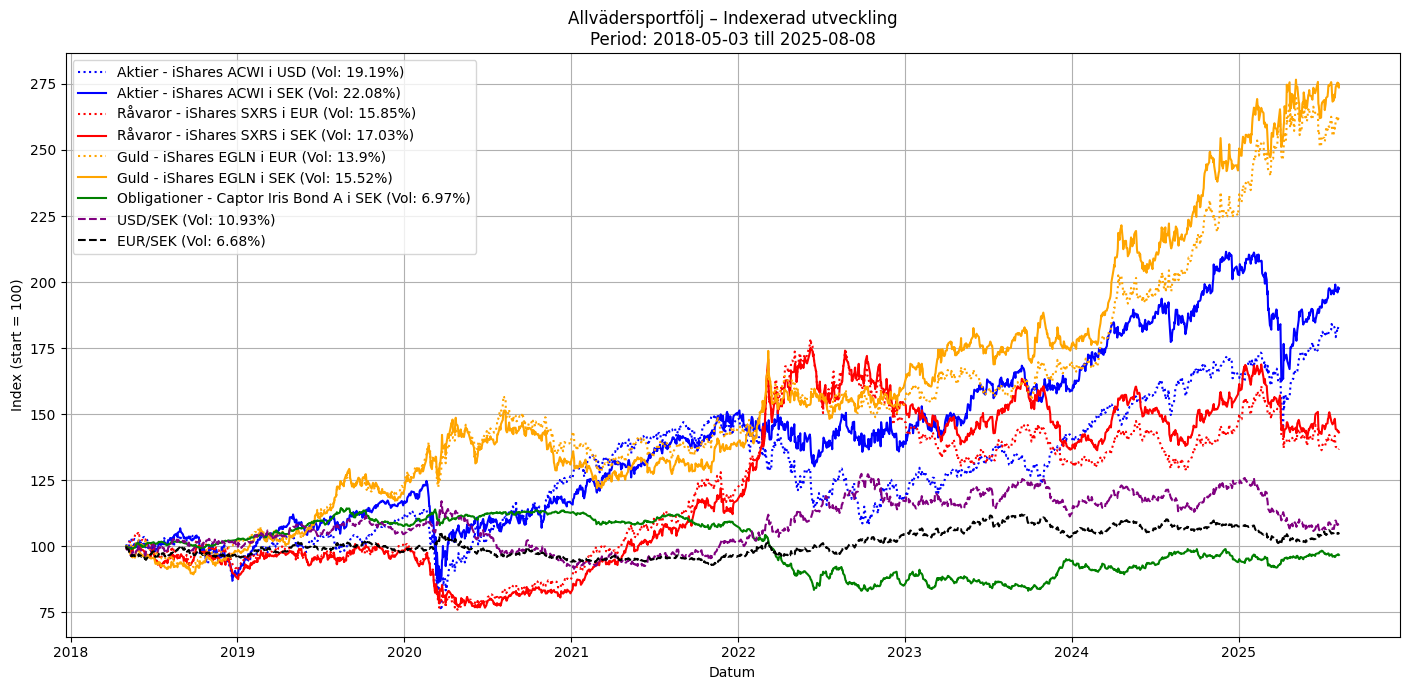
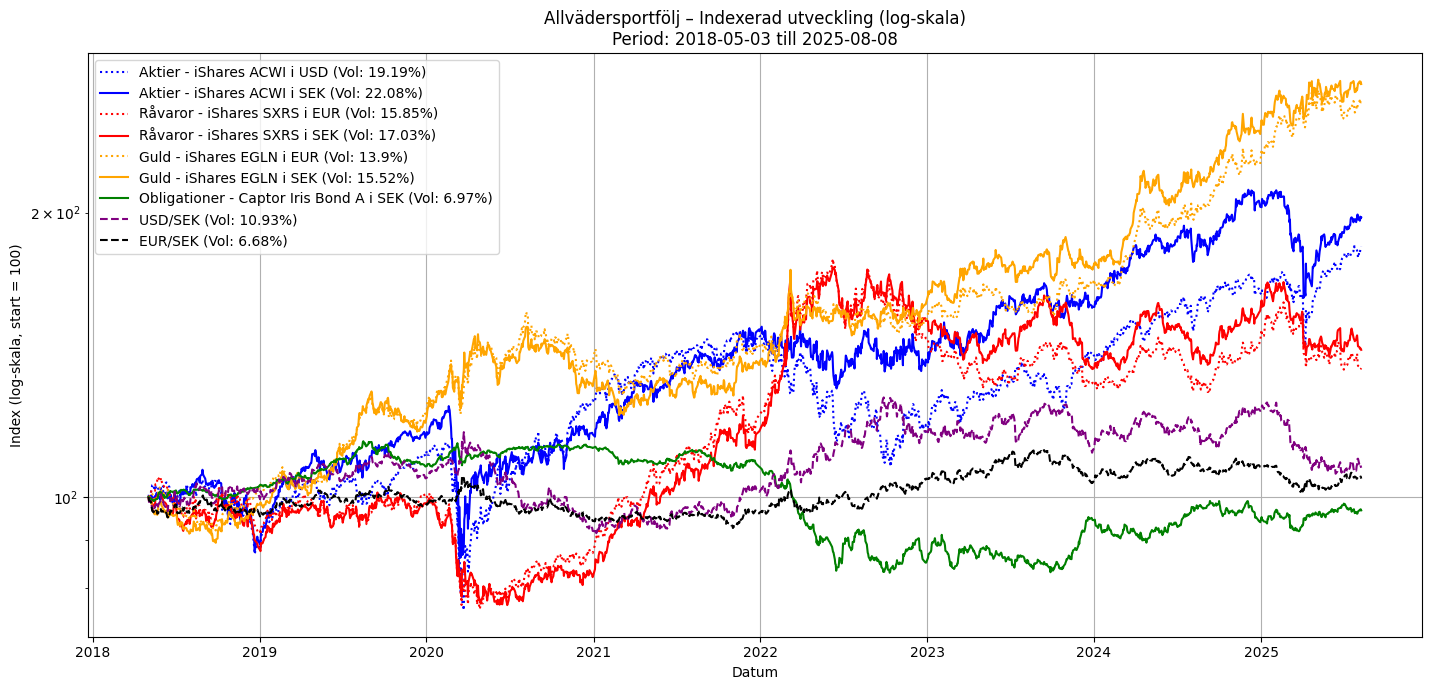
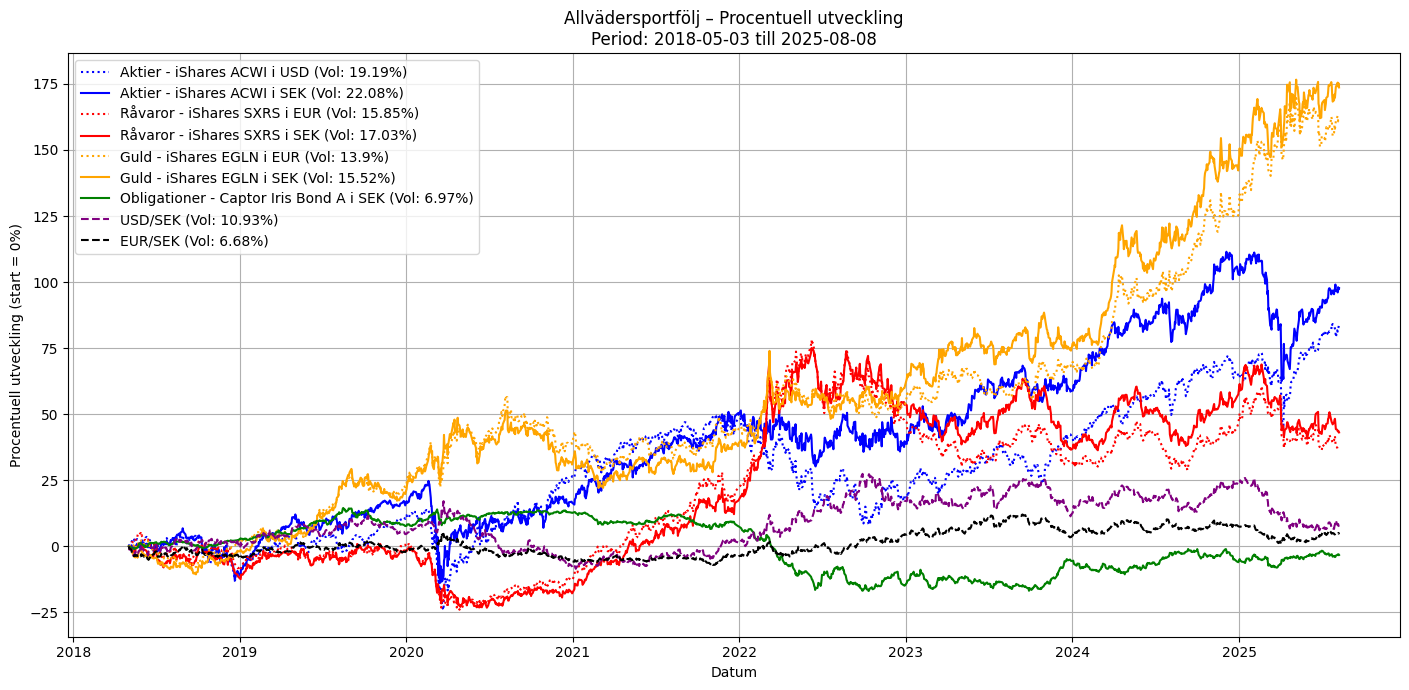
Några uppdateringar… Jag har jobbat med att försöka få tag på data som sträcker sig minst fem år bakåt i tiden till min plot av komponenterna i en enkel allvädersportfölj. Jag fick byta ut alla ETF:er för att lyckas med detta. ACWI-ETF:en och guld-ETF:en borde vara likvärdiga med de som används i den enkla portfölj @Zino beskriver i sin tråd. EN4C har jag dock bytt ut mot SXRS, som följer BCOM, ett råvaruindex. Detta då data för EN4C inte fanns för fem år (jag tror inte ens EN4C har existerat i fem år).
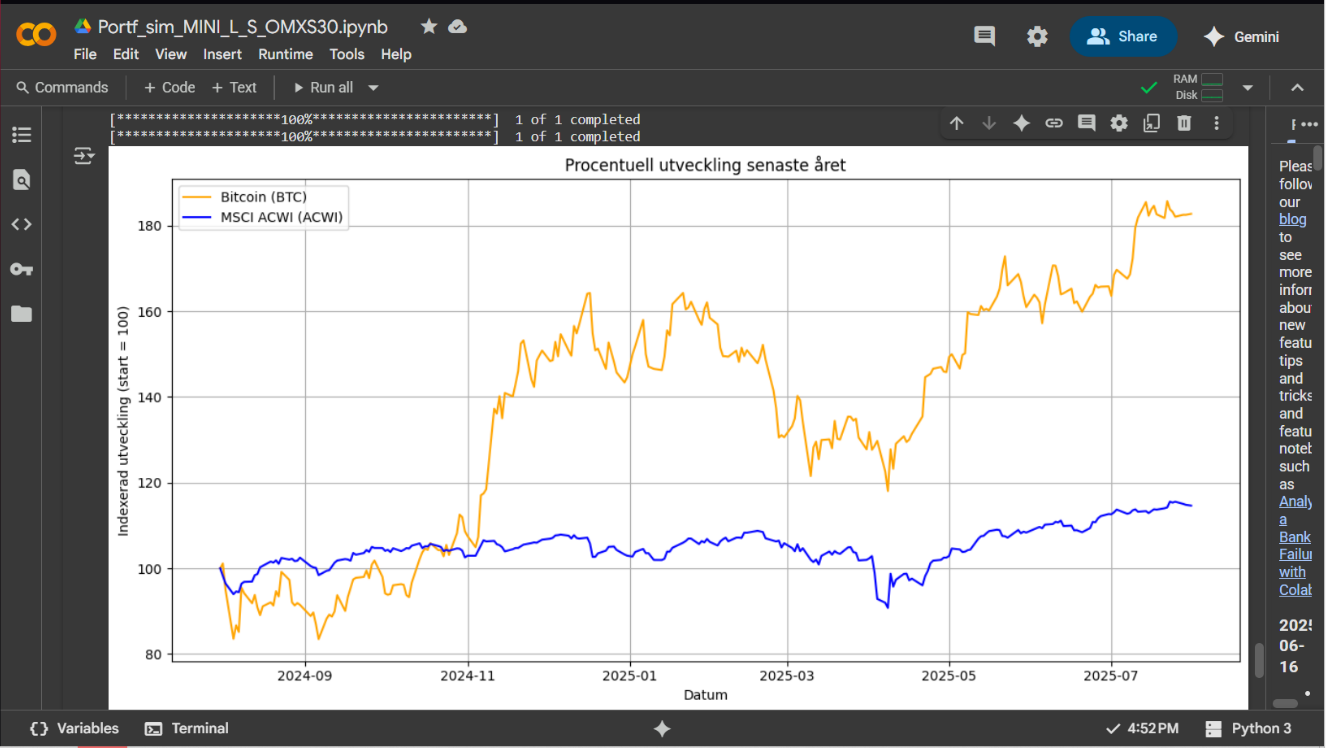
Nedan är en plot för drygt 7 år. För tillfället är det SXRS som är begränsande då det gäller vilken historik jag kan få tag på bakåt i tiden. Volatiliteten för de olika serierna är beräknad som ett snitt över hela tidsperioden.
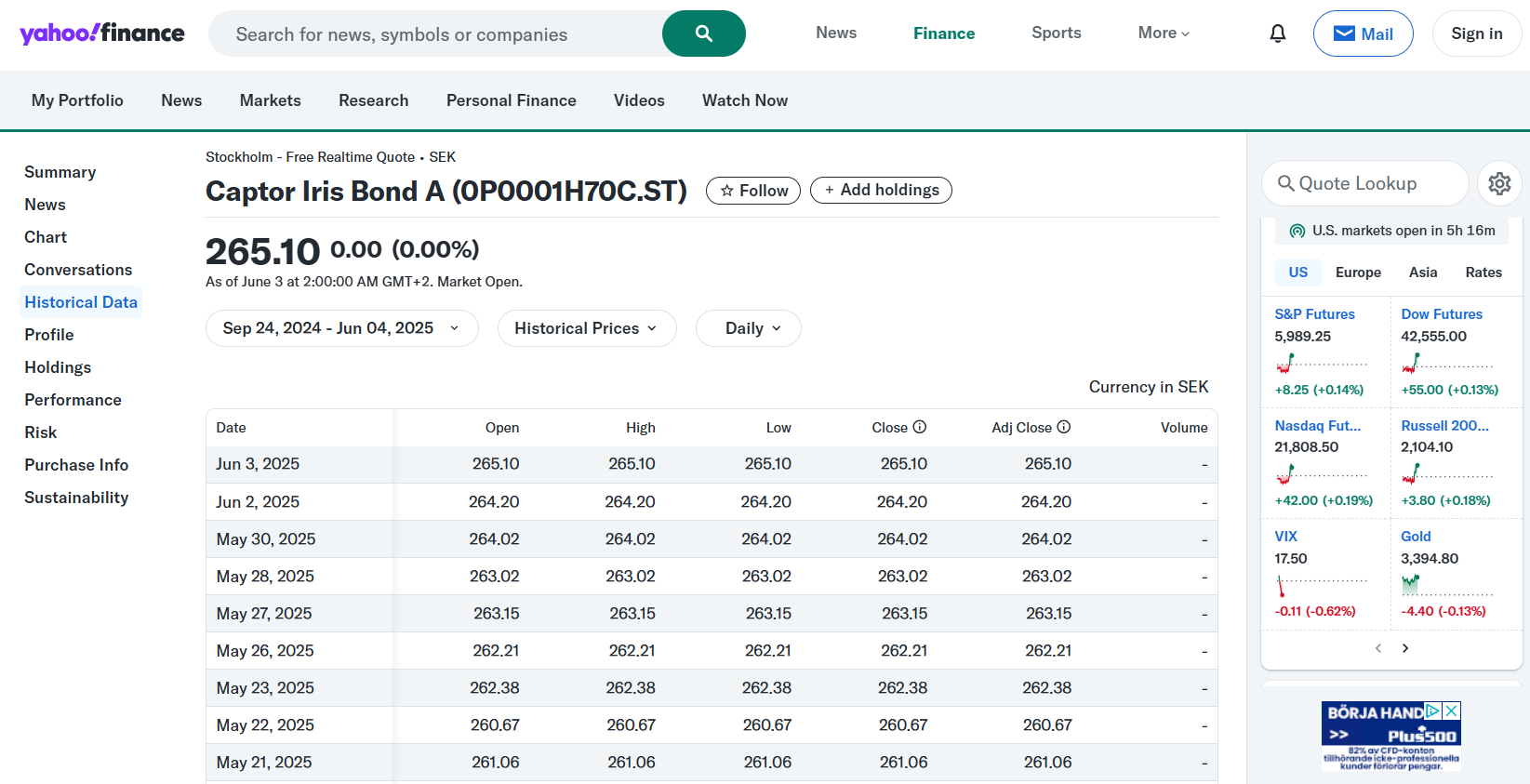
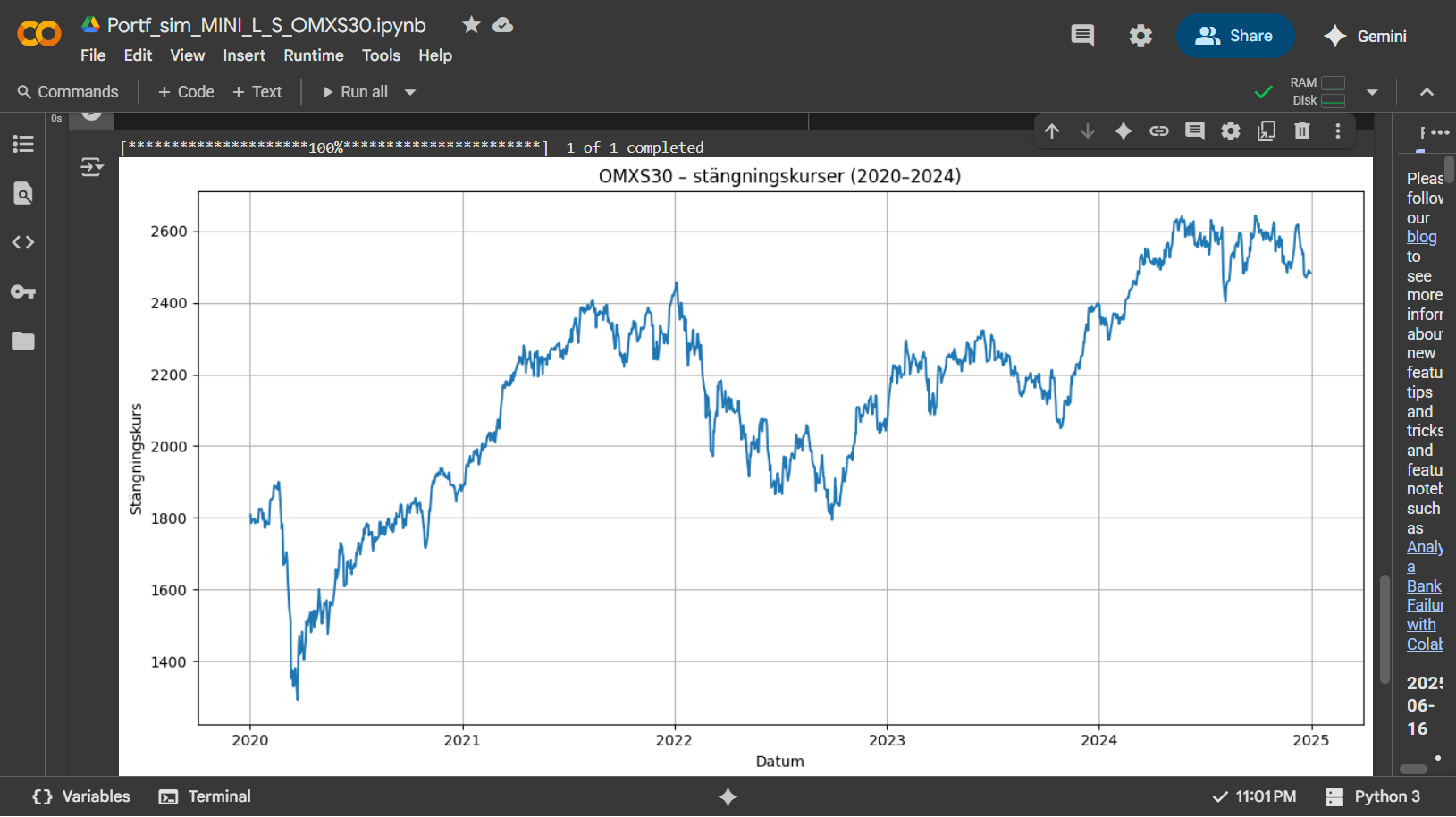
Det finns fortfarande några kosmetiska skavanker i koden, men här nedan är den i sin helhet för den som är intresserad. Jag kör Python-koden i Google Colab och jag har en Excelfil med historiska data för Captor Iris, som ligger på Google Drive och som används för de äldre data som inte finns att tillgå på Yahoo Finance.
kod
import yfinance as yf
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
from google.colab import drive
from matplotlib.ticker import FuncFormatter
# === Välj y-skale-typ ===
# Alternativ: "index", "procent", "log"
y_axis_type = "log"
# End date (för Yahoo)
end_date = datetime.combine(datetime.today().date(), datetime.min.time())
print("End date (för Yahoo):", end_date)
# Använd ett tidigt datum för att hämta all tillgänglig historik
raw_start_date = datetime.today() - relativedelta(years=100) # eller t.ex. 15 år
# Alternativ för en femårsperiod (tidigare kod)
# start_date = end_date - relativedelta(years=5)
# Hämta data: ACWI i USD, SXRS och EGLN i EUR, Captor Iris i SEK, samt EUR/SEK- och USD/SEK växelkurser
acwi = yf.download("ACWI", start=raw_start_date, end=end_date, auto_adjust=False)
print("ACWI loaded:", not acwi.empty)
sxrs = yf.download("SXRS.DE", start=raw_start_date, end=end_date, auto_adjust=False)
print("SXRS loaded:", not sxrs.empty)
egln = yf.download("EGLN.L", start=raw_start_date, end=end_date, auto_adjust=False)
print("EGLN loaded:", not egln.empty)
# Mount Google Drive (om du kör i Colab)
drive.mount('/content/drive')
# === 1. Läs historiska NAV-data från Excel ===
excel_path = "/content/drive/MyDrive/Colab Notebooks/Indata/captor_iris.xlsx"
captor_excel = pd.read_excel(excel_path, parse_dates=["Datum"])
# Konvertera NAV till float
captor_excel["NAV"] = (
captor_excel["NAV"]
.astype(str)
.str.replace(",", ".")
.str.replace(" ", "")
.astype(float)
)
captor_excel.set_index("Datum", inplace=True)
captor_excel.sort_index(inplace=True)
# === 2. Bestäm sista datum i Excel-filen ===
last_excel_date = captor_excel.index.max()
print("\nExcel-data slutar:", last_excel_date.date())
# === 3. Hämta nyare data från Yahoo Finance (om det finns) ===
start_yahoo_date = last_excel_date + timedelta(days=1)
# Debug
print("End date (för Yahoo-download):", end_date)
print("Sista datum i Captor från Excel:", last_excel_date)
print("Startdatum för Yahoo-download:", start_yahoo_date)
# End debug
# Ladda data med download()
captor_yahoo = yf.download(
"0P0001H70C.ST",
start=start_yahoo_date,
end=end_date + timedelta(days=1), # en dag extra för att inkludera gårdag
auto_adjust=False
)
if captor_yahoo.empty:
print("Ingen ny data från Yahoo Finance.") # <– Körs om Yahoo är tom
captor_combined = captor_excel.copy() # <– ingår i if-blocket
else:
print("Yahoo Finance-data hämtad.") # <– Körs annars
# === Säkert extrahera 'Close' som NAV från Yahoo ===
if isinstance(captor_yahoo.columns, pd.MultiIndex):
# Yahoo ger MultiIndex: ('Close', '0P0001H70C.ST') – vi väljer första nivån = "Close"
captor_yahoo = captor_yahoo.loc[:, pd.IndexSlice["Close", :]]
else:
captor_yahoo = captor_yahoo[["Close"]]
# Byt kolumnnamnet till "NAV"
captor_yahoo.columns = ["NAV"]
# Standardisera indexnamn och sortering
captor_yahoo.index.name = "Datum"
captor_yahoo.sort_index(inplace=True)
# === 4. Slå ihop Excel- och Yahoo-data ===
captor_combined = pd.concat([captor_excel, captor_yahoo])
captor_combined = captor_combined[~captor_combined.index.duplicated(keep="last")]
# === 5. Filtrera enligt datumintervall ===
# === Gäller oavsett if/else ovan ===
captor_combined = captor_combined[
(captor_combined.index >= raw_start_date) &
(captor_combined.index <= end_date)
]
# Kontroll
if captor_combined.empty:
print("⚠️ Varning: captor_combined är tom efter datumfiltrering!")
else:
print("✅ captor_combined klar – sista datum:", captor_combined.index.max())
# Debug
print("Excel slutar:", last_excel_date.date())
print("Hämtar från start:", start_yahoo_date, "till", end_date)
print("Yahoo-data:\n", captor_yahoo.tail())
print("Captor Iris (kombinerad) loaded:", not captor_combined.empty)
usdsek = yf.download("USDSEK=X", start=raw_start_date, end=end_date, auto_adjust=False) # USD/SEK
print("USD/SEK loaded:", not usdsek.empty)
eursek = yf.download("EURSEK=X", start=raw_start_date, end=end_date, auto_adjust=False) # EUR/SEK
print("EUR/SEK loaded:", not eursek.empty)
# Testa: skriv ut första 5 raderna av varje
print("ACWI (USD):\n", acwi.head(), "\n")
print("SXRS.DE (EUR):\n", sxrs.head(), "\n")
print("EGLN.L (EUR):\n", egln.head(), "\n")
print("Captor Yahoo data:\n", captor_yahoo.head(), "\n")
print("Captor Yahoo data:\n", captor_yahoo.tail(), "\n")
print("Captor Iris (SEK):\n", captor_combined.head(), "\n")
print("Captor Iris (SEK):\n", captor_combined.tail(), "\n")
print("USDSEK=X:\n", usdsek.head(), "\n")
print("EURSEK=X:\n", eursek.head(), "\n")
# Säker extraktion av 'Close' även om vi får en DataFrame med MultiIndex (efter nya yfinance-versioner)
def extract_close(df, name):
if isinstance(df.columns, pd.MultiIndex):
return df.loc[:, ("Close", name)]
else:
return df["Close"]
# Byt namn på serierna
acwi_close = extract_close(acwi, "ACWI")
acwi_close.name = "ACWI_USD"
sxrs_close = extract_close(sxrs, "SXRS.DE")
sxrs_close.name = "SXRS_EUR"
egln_close = extract_close(egln, "EGLN.L")
egln_close.name = "EGLN_EUR"
captor_close = captor_combined["NAV"]
captor_close.name = "Captor_SEK"
usdsek_close = extract_close(usdsek, "USDSEK=X")
usdsek_close.name = "USDSEK"
eursek_close = extract_close(eursek, "EURSEK=X")
eursek_close.name = "EURSEK"
start_dates = [
acwi_close.first_valid_index(),
sxrs_close.first_valid_index(),
egln_close.first_valid_index(),
captor_close.first_valid_index(),
usdsek_close.first_valid_index(),
eursek_close.first_valid_index()
]
start_date = max(start_dates) # senaste gemensamma startdatum
print("Automatiskt valt gemensamt startdatum:", start_date, "\n")
acwi_close = acwi_close[(acwi_close.index >= start_date) & (acwi_close.index <= end_date)]
sxrs_close = sxrs_close[(sxrs_close.index >= start_date) & (sxrs_close.index <= end_date)]
egln_close = egln_close[(egln_close.index >= start_date) & (egln_close.index <= end_date)]
captor_close = captor_close[(captor_close.index >= start_date) & (captor_close.index <= end_date)]
usdsek_close = usdsek_close[(usdsek_close.index >= start_date) & (usdsek_close.index <= end_date)]
eursek_close = eursek_close[(eursek_close.index >= start_date) & (eursek_close.index <= end_date)]
# Kolla startdatum för varje individuell serie (innan sammanslagning)
for name, series in [
("ACWI", acwi_close),
("SXRS", sxrs_close),
("EGLN", egln_close),
("Captor", captor_close),
("USDSEK", usdsek_close),
("EURSEK", eursek_close)
]:
print(f"{name} – start: {series.first_valid_index()}, slut: {series.last_valid_index()}, antal: {len(series)}")
# Kombinera dem i en gemensam DataFrame
df = pd.concat([acwi_close, sxrs_close, egln_close, captor_close, usdsek_close, eursek_close], axis=1)
df.dropna(inplace=True)
# Ta bort alla rader där någon av dem saknas (t.ex. helgdagar eller stängd börs)
df.dropna(inplace=True)
# Kontroll om DataFrame blev tom efter sammanslagningen
if df.empty:
raise ValueError("Inga gemensamma datum – datan kan vara tom eller sakna överlapp.")
# Kontrollera upplösningen på data och hur långt bak i tiden data finns
print("Frekvens:\n", pd.infer_freq(df.index))
print("Antal datapunkter:", len(df))
print("Startdatum:", df.index.min())
print("Slutdatum:", df.index.max())
# Omvandla till SEK
df["ACWI_SEK"] = df["ACWI_USD"] * df["USDSEK"]
df["SXRS_SEK"] = df["SXRS_EUR"] * df["EURSEK"]
df["EGLN_SEK"] = df["EGLN_EUR"] * df["EURSEK"]
indexed_cols = []
for col in ["ACWI_USD", "ACWI_SEK", "SXRS_EUR", "SXRS_SEK",
"EGLN_EUR", "EGLN_SEK", "Captor_SEK", "USDSEK", "EURSEK"]:
if y_axis_type == "procent":
df[f"{col}_transformed"] = (df[col] / df[col].iloc[0] - 1) * 100
else: # "index" eller "log", indexera utvecklingen (börja från 100)
df[f"{col}_transformed"] = (df[col] / df[col].iloc[0]) * 100
indexed_cols.append((f"{col}_transformed", col)) # sparar både nya och ursprungliga namnet
# Beräkna dagliga logaritmiska avkastningar
cols_for_vol = ["ACWI_USD", "ACWI_SEK", "SXRS_EUR", "SXRS_SEK", "EGLN_EUR", "EGLN_SEK", "Captor_SEK", "USDSEK", "EURSEK"]
log_returns = np.log(df[cols_for_vol] / df[cols_for_vol].shift(1))
# Beräkna årlig volatilitet (standardavvikelse * sqrt(252))
volatility = log_returns.std() * np.sqrt(252)
# Konvertera till procent, t.ex. 0.25 → 25.0%
volatility_pct = (volatility * 100).round(2)
# Plot
plt.figure(figsize=(14, 7))
# Definiera stil för varje kolumn (kan anpassas!)
style_map = {
"ACWI_USD": ("Aktier - iShares ACWI i USD", "blue", ":"),
"ACWI_SEK": ("Aktier - iShares ACWI i SEK", "blue", "-"),
"SXRS_EUR": ("Råvaror - iShares SXRS i EUR", "red", ":"),
"SXRS_SEK": ("Råvaror - iShares SXRS i SEK", "red", "-"),
"EGLN_EUR": ("Guld - iShares EGLN i EUR", "orange", ":"),
"EGLN_SEK": ("Guld - iShares EGLN i SEK", "orange", "-"),
"Captor_SEK": ("Obligationer - Captor Iris Bond A i SEK", "green", "-"),
"USDSEK": ("USD/SEK", "purple", "--"),
"EURSEK": ("EUR/SEK", "black", "--")
}
for transformed_col, original_col in indexed_cols:
label, color, style = style_map.get(original_col, (original_col, "grey", "-"))
vol = volatility_pct.get(original_col, None)
if vol is not None:
label += f" (Vol: {vol}%)"
plt.plot(df.index, df[transformed_col], label=label, color=color, linestyle=style)
start_str = df.index.min().strftime("%Y-%m-%d")
end_str = df.index.max().strftime("%Y-%m-%d")
title_map = {
"index": "Indexerad utveckling",
"procent": "Procentuell utveckling",
"log": "Indexerad utveckling (log-skala)"
}
plt.title(f"Allvädersportfölj – {title_map[y_axis_type]}\nPeriod: {start_str} till {end_str}")
plt.xlabel("Datum")
plt.legend(loc="upper left")
plt.grid(True)
plt.tight_layout()
if y_axis_type == "procent":
# Procentformat på y-axeln
def percent_formatter(x, pos):
return f"{x:.0f}%"
plt.gca().yaxis.set_major_formatter(FuncFormatter(percent_formatter))
plt.ylabel("Procentuell utveckling (start = 0%)")
plt.yscale("linear")
elif y_axis_type == "log":
if (df[[col for col, _ in indexed_cols]] <= 0).any().any():
raise ValueError("Log-skala kräver positiva värden – minst ett värde är ≤ 0.")
plt.ylabel("Index (log-skala, start = 100)")
plt.yscale("log") # OBS: fungerar inte om några värden ≤ 0
else: # "index"
plt.ylabel("Index (start = 100)")
plt.yscale("linear")
plt.show()
Tillägg: Nu även med log-skala på y-axeln (valbart i koden).