Helt crazy-graf enligt mig. Kommer ihåg hur mycket skit Amazon fick när de gick med förlust “hela tiden”. Eller Spotify.
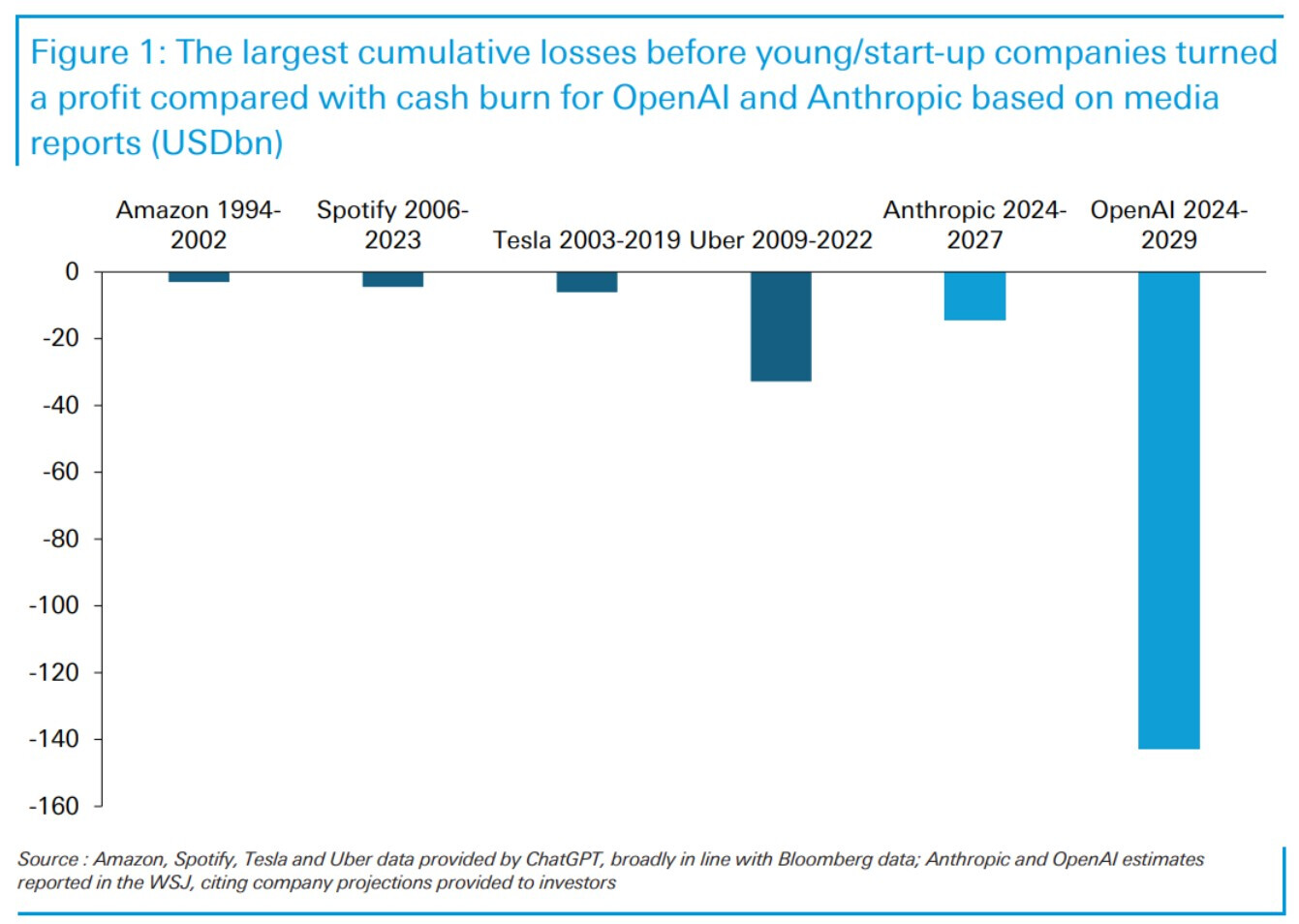
Källa: Thematic Research: DB CoTD: The largest start-up losses in history
Ping @Andre_Granstrom
Helt crazy-graf enligt mig. Kommer ihåg hur mycket skit Amazon fick när de gick med förlust “hela tiden”. Eller Spotify.
Källa: Thematic Research: DB CoTD: The largest start-up losses in history
Ping @Andre_Granstrom
Det här är väl en anledning till varför folk pratar om en AI bubbla.
Företagen pumpar in så extremt mycket pengar i AI modellerna och de får tillbaka så otroligt lite i jämförelse att situationen helt enkelt är ohållbar.
OpenAI är värst, men alla företag som utvecklar modeller har samma problem.
“Too big to fail”?
Känns inte helt orimligt att OpenAI trots att de är first movers inte blir last man standing när the dust has settled.
Att jämföra kassaflöde med resultat är ju inte så rimligt och lite click-baitigt. Man borde ju ha jämfört med de andra bolagens kassaflöde om det enda man kan uppskatta för OpenAI och Anthropic är just free cash flow.
Jag tvivlar inte på att OpenAI gjort enorma förluster, men en hel del av cashen de bränner har ju gått åt till att skapa något som har ett värde (capex), så allt negativt cash flow är ju inte förlust, utan matchas av en tillgång på balansräkningen.
Det som är intressant är att det finns bra open-source-modeller som ligger aningen efter de kommersiella, så hur mycket av det skapade värdet “finns kvar?” Säg att det är det senaste årets arbete som fortfarande ligger före, allt innan dess är bränt av open source och öppet tillgänglig kunskap nu.
Jag gissar att alla hoppas nå någon slags singularitet, att bryta igenom en barriär där neurala näten-plötsligt förbättrar sig själva och plötsligt blir bättre exponentiellt utan gräns. Den som kommer dit först (om någon), kommer köra ifrån alla andra och ta hela marknaden (och världen, och mänskligheten, och planeten, och universum, typ). Science-fiction-mässigt är det spännande, men det återstår att se hur länge folk är redo att fortsätta pumpa in pengar för att få hänga med om det händer.
Samtidigt är jag entusiast, och ser stor nytta i det som redan är framtaget. Men det finns många företag och open source som kan ge det nu. Jag är inte säker på att det finns enormt värde i något enskilt företag av det, även om nyttan för mänskligheten finns där.
Nvidia har precis släppt info om sin nya generation, där träningen blir 6x billigare (iirc), vilket gör det både lättare för små organisationer att återskapa det giganterna tagit fram, men också gör det möjligt för giganterna att ta ett steg framåt och träna ännu större grejer.
Det känns inte som att värdet är så mycket i näten de tagit fram, utan i kunskapen och expertisen de har fått genom att göra det. Sitter den expertisen i företaget eller i personerna i organisationen? Vi ser att personer rör på sig, knoppar av till nya företag och konstellationer hela tiden, så det verkar inte finnas mycket stabilt värde för ett specifikt företag där, om folk bara kan lämna hela tiden (och gör det).
Jag tror detta är dödsdömt. Helt enkelt finns inget som tyder på att de modeller och metoder som används skalar effektivitetsmässigt. De växer bara i storlek och komplexitet minst lika mycket som deras prestanda.
Dessutom är den stora källan till träningsdata (internet) för evigt “förgiftad” av AI innehåll från något år sen och framåt. Det går inte att stoppa tillbaka den anden i flaskan nu.
Läste en intressant analys häromdagen som var inne på just det här att det är en investeringsbubbla och inte en teknikbubbla.
Alla är väl rätt eniga om att AI är/kommer att bli transformativ för samhället men att det har pumpats in så mycket pengar i AI så att det nu är enklare att bygga fler datahallar istället för att utveckla bättre teknik. Analysen menade på att det är först när investeringsbubblan spricker som innovationen verkligen kommer att ta fart.
Nu kommer vi ju in på något som är väldigt mycket mer svårt att bedöma än det faktum att man jämför två objektivt helt olika nyckeltal med varandra.
Men om vi ändå går dit så är det ju inte självklart att en värdet på en proprietär lösning bara är det den rent tekniskt har i försprång mot en open source-lösning. Är Excel bara värt exakt det dess tekniska försprång är jämfört med bästa fria lösningen, eller finns det ett värde i varumärke, spridd kunskap och “mindshare”?
Mycket av OpenAI:s capex ska ju dessutom gå till fysisk infrastruktur (datacenter) nu när de går från hyrd compute till egen-hostad. Det kostar ju enormt mycket cash flow, men lär ju inte direktavskrivas och hamna på nedersta raden år ett.
OpenAI:s spend går förstås ifrågasätta. Men det förändrar inte att förlust och free cash flow är väldigt olika saker.
GPUerna i såna datacenter har väl en livslängd på ca 3 år, och de kräver mycket i drift under tiden (el och vatten till kylning).
Håller med. Men hårdvaran ruttnar fort, i takt med att Nvidia släpper nya generationer som är mer kompakta och kan ha fler Watt träningskapacitet i samma rack, och mer träning per Watt. Ju mer träning som kan sättas ihop i en låglatens-klump, ju effektivare träning och större nät. Hela klumpen måste finnas i ett enda rack/backplane, verkar det som.
Så de gamla racken blir helt meningslösa för bleeding edge när nya rack kan göras som är tätare. Det är inte att man adderar kapacitet på ett kluster, det gamla åker väck.
När det gäller hur enkelt det är att byta modellerna, så… enkelt. Kolla i AI-tråden där det postats grafer över tid om hur workflowen hoppar från AI-modell till AI-modell allteftersom nya släpps, där det inte verkar finnas någon lojalitet eller behov av legacy alls. Från en dag till en annan så skiftar alla workloads bara över till den nya. AI-workloads är såpass fuzzy att det bara är att skifta över indatan till en ny modell, och så fattar den vad som ska göras. Det är lite definitionen av dessa workloads, att man inte masserat in det till specifika API:er.
Kolla denna graf, t ex:
Inget av det du skriver här är något jag inte håller med om eller har sagt emot. Jag använder själv många modeller och byter hela tiden.