Jag blev nyligen hänvisad till forumets stora tråd om vad folk har för bolån. Den är lång och jag läste inte såå mycket, men av en slump hittade jag ändå ett inlägg som kommenterade att det är lite synd att datat var så ostrukturerad (jag håller med!) och pekade på ett annat forum, byggahus.se, som har motsvarande rapporterad data, men i strukturerat format.
Detaljer kring elva tusen bolån, wow vad spännande tänkte jag!
Så jag skrev en scraper, fyllde på med lite annan data, filtrerade lite och plottade.
Här är ett första utkast. Det är lite slarvigt gjort och jag ska utforska mer själv senare, men just nu måste jag ta hand om annat.
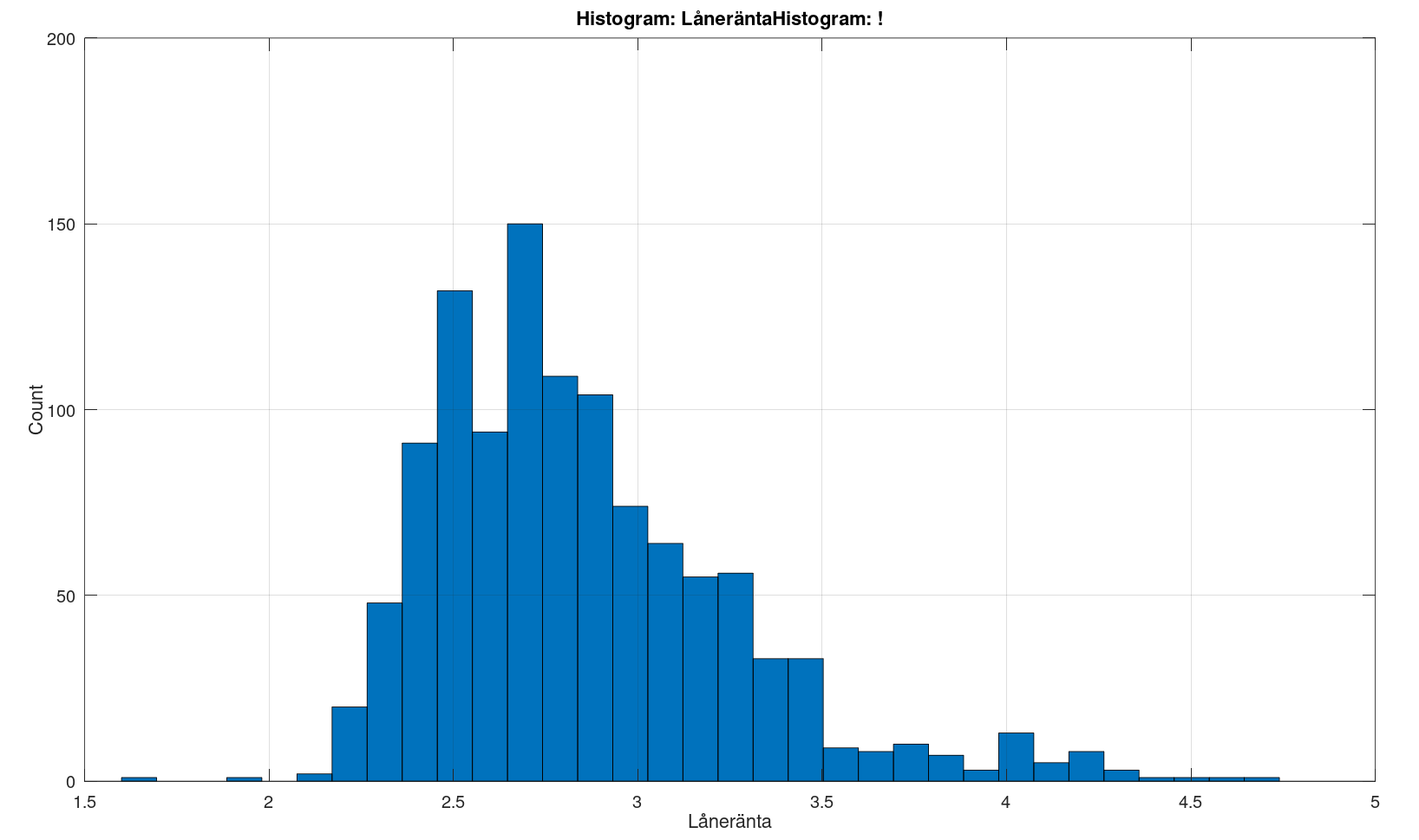
Detta är rörliga lån på 1-7 milj från de senaste 12 månaderna, med en belåningsgrad mellan 40-85 med några outliers bortplockade. Det blev 1137 lån kvar. Jag har zoomat efter eget tycke på de glidande medelvärdena.
Vad reagerar ni på? Vad hade man mer velat se?
Själv är jag spontant lite förvånad att inte belåningsgrad verkar korrelera mer med vilken ränta man fått.
Disclaimer: Tänk på att detta är självrapporterade låneuppgifter.
Koderna är till stor del skriven av ChatGPT och jag har inte korrat såå mycket, så kan finnas brister.
Senaste 12 månaderna är rätt ointresserant eftersom riksbanken har sänkt runt 1,5% under den perioden, du behöver nog justera datan för det om du vill ha användbara grafer.
Ja så är det såklart.
Jag lade in styrräntan också och tittade på differensen mellan låneränta och styrränta istället.
Då blir fördelningen mer normalfördelad, och det beror nog till stor del på fördelningen i tid i datat. Fortfarande lite större svans till höger (fler lån till bankens fördel) än till vänster (bra lån för oss konsumenter).
Trenderna förändras dock inte och kurvan för belåningsgrad är fortfarande platt!
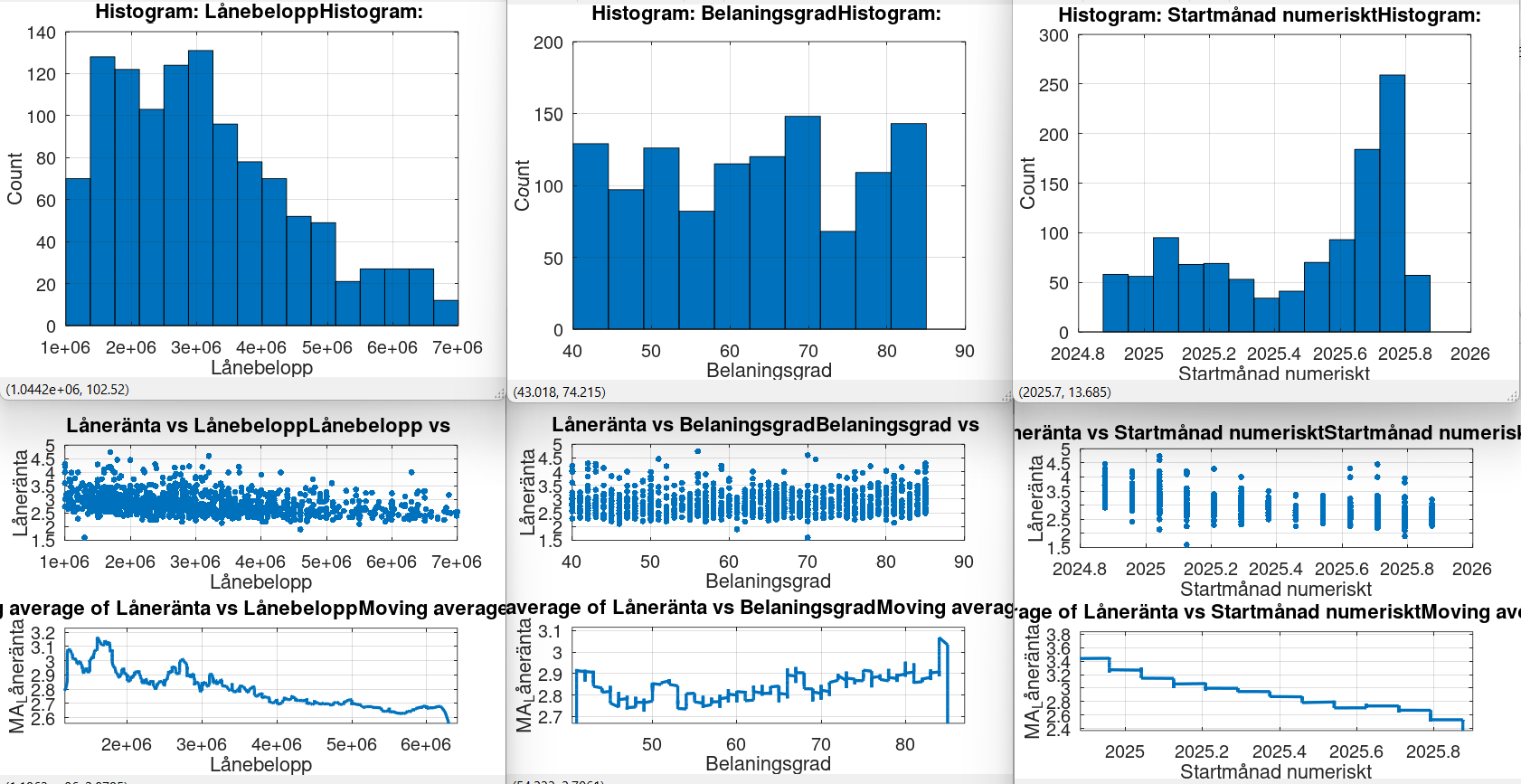
Storkundsrabatt syns både i mina första och andra bilder, att räntan går ner med ökande lånevolym (längst ner t.v.). Och det är intutivt logiskt. Fördelen med att titta på data är att man inte bara ser att det går ner, utan man får även en uppfattning om hur mycket det påverkar.
Oavsett tighta intervall på lånebelopp eller annat har jag inte hittat något filter som visar en trend för att belåningsgrad skulle spela någon roll. Jag har testat flera filterstorlekar och belopp.
Och det som stör mig med det är att jag inte kan se logiken…
Belåningsgrad är ju rimligen hårt kopplat till risk från bankens sida, vilket borde synas i avkastningskrav?
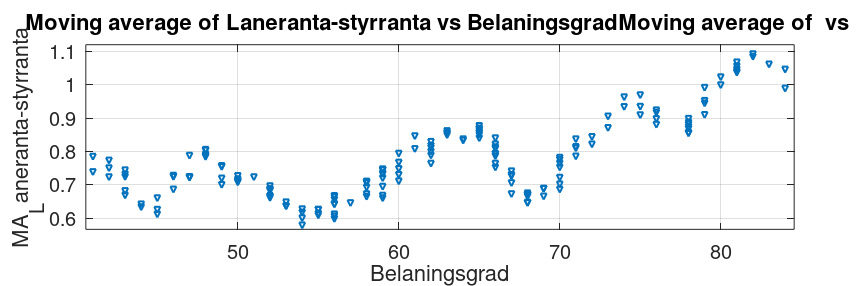
Du kan ju filtrera på nån av de transparenta bankerna som tar hänsyn till belåningsgrad, t.ex. Skandiabanken. Där borde du se mönstret tydligt, annars är ju nåt fel.
Enkelt och mycket bra förslag!
Och resultatet är också det förväntade. Tar man bara SBAB och Skandia så ser man tydligt en trend. Ca 20 punkter bättre vid ish 40% belåning jämfört med 85%.
Så datat kanske stämmer. Jag började tänka om det kan vara så att belåningsgraden inte spelar så stor roll därför den avgör risken när lånet skiter sig, snarare än risken att lånet skiter sig, vilket banken bryr sig betydligt mer om.
Jag har tänkt att vi skulle kunna ta in sådan data i communityn. Vilket format skulle du vilja ha det i för att det ska bli enkelt att göra en rapport på?
Ang. format:
Jag hävdar både här och på jobbet att AI-botarna är bra på att konvertera datatyper/skriva enkla script för dito. Så jag tror inte det spelar så stor roll, bara det är konsekvent!
Visionen om vad man vill åstadkomma är viktigare.
”Vilka är frågorna?”
Min ursprungsfråga var egentligen
”Vilken ränta borde jag försöka förhandla mig till och hos vilka banker tror jag det är lättast?”
När jag hittade ett dataset så gjorde jag vad man gör nu för tiden med data, kastade AI på det
Men sen väcktes min nyfikenhet också! Typ, “kan man lära sig något kul om hur bankerna fungerar” eller “kan ett datadrivet underlag bidra i samtal kring samhälle/politik med vänner/kollegor?”
Bara bundna/obundna eller alla lån tagna senaste 12 mån?
Byggahus har användare som rapporterar flera lånedelar som är bundna/obundna, då kan räntan bli lidande och lånestorleken vara liten, eller jättebra ränta på litet lån.
Finns ganska mycket att tänka på för att detta ska bli bra.
T ex finner jag postnummer och bolånebank som en av de viktigare grejerna att kunna slå på.
T ex inte så rimligt att jämföra räntor från Vilhelmina för att fundera på räntor i central storstad.
@janbolmeson Måste finnas en analytiker eller annan yrkesgrupp i forumet som kan komma med inspel på vad som absolut måste vara med användas för databeredningen.
För mig som ingenjör så får datan gärna vara inmatad som en sträng i CSV-format om det bara är ett dussintal datapunkter per post (och bara något tusental poster). Då är det superlätt att hantera i excel/google sheets. Större mängder bör nog hanteras i en riktig databas istället.
Det är lättare att få bra ränta som helkund, gärna toppat med nån onödigt dyr försäkring och liknande. Så det är svårt att få fram hela sanningen i sådana här underökningar.
Själv betalade jag 0 kr för buljongen på ICA senast, men givetvis får inte alla det priset.
BIlderna jag visat är på rörligt. Det och övriga filter står i första inlägget
Det har du helt rätt i, det stökar till statistiken. Svårt att filtrera bort dock… Titta lite på datat och det är ungefär tre gånger så många rader med “olika” lån som det är unika användare. Så det är nog rätt mycket som du säger… Det sabbar ju tyvärr hela datasettet lite, för vissa analyser @janbolmeson Om jag hade gjort databasen hade jag gjort så att man kan mata in alla de olika delarna av sitt lån samtidigt och att alla de delarna får något ID så att man kan koppla ihop de.
Då hade man också kunnat svara på tex frågor som
Hur vanligt är det att folk delar upp sitt lån? Vinner de något på det?
Bankerna brukar ju förespråka att man ska dela upp om man vill binda för att sprida riskerna, medan forummet ofta säger att man ska akta sig för att låsa in sig i banken genom att aldrig kunna flytta hela lånet tex.
Japp så är det! Jag har trixat och fixat med olika mer specifika filter för mitt case, men det blir ju snabbt bedömningssport av vad man ska ta med och inte. Och i slutändan får man ändå ta det med en rejäl nypa salt. Här i forumet försökte jag hålla det väldigt allmänt och bara visa lite av statistiken för att se om andra var intresserade.
Jag säger inte att du har fel ang excel/sheets. Men jag personligen håller mig gärna långt borta från de vertygen och använder hellre programmering. Python/MATLAB/Octave. LLMerna är bra på att skriva/hjälpa till med de koderna också. Och kan man hålla sig till bara siffror så är det inga problem att jobba med mycket fler datapunkter än vad vi kommer kunna generera i det här formuet i en vanlig csv-fil. Strängar funkar ok också. Även om vi får in drömmigt mycket data kommer man fortfarande kunna träna ett neuralt nätverk/göra PCA/regressionsanalys etc med vanlig hemmadator på minuter.
Det är helt sant! Jag tror dock man skulle kunna landa rätt bra kvantitativt för vissa samband om man har lagom mycket data.
Typ koefficienten för storkundsrabatt vid stor lånevolym.
Hur mycket info finns per bolån i nuläget? Kör analyserna i R och ta in så mycket info det bara går. Matriser på en miljon rader är inte ett problem där och ev justeringar blir lätta att göra
Detta är ju bara databearbetningsverktygen, lagringsformatet får rimligen vara ett db format, SQL/noSQL är väl rimligast. Om det bara rör sig om ett par tusen poster så är det nog rätt skitsamma vad som körs.
För egen del ligger det i linje med mina anekdotiska observationer: högt lånebelopp är bra för förhandlingen, belåningsgrad spelar mindre roll och har en u-formad kurva. För en given summa (huskostnad) ger det antagligen bäst förhandlingsposition att maxbelåna.
janbolmeson
(Jan Bolmeson)
delade upp denna diskussion i ett nytt ämne
17