Det har du helt rätt i, men jag tänkte mig nog mer att det finns många som kommer tro dig vara bättre än en AI på saker som en AI är bättre på. Lite likt att de flesta tror sig vara bättre än genomsnittet, trots att de inte är det.
Inom saker där det inte krävs så många parametrar som för bild generering så stämmer det nog, men för LLM som ChatGPT så stämmer det nog inte alls. Det krävs så mycket att skapa dem att jag gissar att Open Source kommer ligga flera år bakom de stora företagen. Det är ju inte bara datorkraften utan även tillgången på stora mängder bra data som krävs.
Håller med dig till viss del. Jag tror dock man överskattar hur “bra” datan måste vara. Ha i åtanke att AI:n enkelt kan sortera ämnen och kategorier, t ex vardaglig chat, blogginlägg, nyhetsartiklar… Om det är något internet har så är det information.
Givetvis kan man göra en bättre och specialiserad AI med snabbare träning om man handplockat data, men för en generell AI som ChatGPT så ska den ju tränas på allt.
Jag är även nyfiken på hur du menar att bildgenerering inte kräver många parametrar. Det behövs både nån miljard bilder och metadata för att träna modeller med bild-output.
Men det ska bli spännande att se hur som helst. Jag vågar som sagt gissa på att vi har fri tillgång till en AI på ChatGPTs nivå om 6-12 månader. Visst, den kommer säkert vara smutsigare och med mer synliga sömmar, men inte värre än ChatGPT skulle vara om den inte filtrerades och begränsades.
Jepp, stable diffusion använde 5 miljarder bilder vid sin träning. Men modellen har knappt 1 miljard parametrar. Tittar vi på Dall-e 2 så har den 3,5 miljarder parametrar. Om vi jämför det med ChatGPT som har 175 miljarder så är det typ 2 storleksordningar större.
Och jag skulle våga påstå att text-bild generering är väldigt långt kommen, det behövs inte extremt mycket mer av modellerna för att vara användbara. Jag skulle dock säga att jag gärna hade sett att LLM som ChatGPT skulle varit 10-100 gånger bättre än de är idag.
Edit: det skulle betyda att en riktigt bra LLM behöver vara 10000 gånger större än en text-bild för att vara på samma nivå.
Jag använder redan AI-bildgenerering i mitt jobb, dagligen. Det är utan tvekan användbart, även om man måste hjälpa till med manuellt arbete. Jag är iofs överintresserad, men är säker på att min branch (design) är en av dem som kommer drabbas hårt.
Läste om precis detta för bara en timme sedan:
Personligen är jag inte orolig, eftersom jag har en RT-ekonomi, men även för att mitt specifika fält inte kommer vara det första som ryker. Och när min branch drabbas har jag sannolikt bidragit till den utvecklingen snarare än stannat upp den.
Med detta sagt så är det långt mellan dagens Dalle/Stable Diffusion fram till faktiskt realistiska bilder. Använder man dem ett tag ser man snart begränsningarna. Ett kul experiment jag hittat på, ett slags Turing-test, är att be om en upp-och-nedvänd version, eller en med inverterade färger. T ex “dog with clown costume and glasses, upside-down”. Har aldrig lyckats få något bra resultat med det.
Så användbara, ja, men det var även GPT-J 6B.
Jag, med brasklappen att jag är bildmänniska, tycker att dagens AI är typ 2 storleksordningar bättre på textgenerering än bildgenerering. På så sätt att den är mycket bättre på att lura mig.
Jag tänker att branschen snarare kommer ändras än försvinna, någon måste ju dels alla dessa modeller och dels måste någon avgöra vad som är bra och vad som måste göras om.
Spännande, aldrig tänkt på det. Ska testa nästa gång.
Oj vad vi har olika bild av hur det är, men vem vet, min bild behöver inte vara sann. Härligt att höra ett nytt perspektiv.
Detta är viktigt, främst då enbart har small AI och inte generell AI. Iaf idag, och under lång tid framöver.
Detta stämmer väl inte helt, det är väl även en forskning i vilka egenskaper som kan uppstå, dvs hur emergence fungerar. På en intervju så hävdade OpenAIs vd att ett stort ögonblick var när GPT-1 kunde förutspå om en recension på Amazon var en like upp eller ner utifrån orden.
Jag skulle påstå att hela LLM går ut på att testa hur nära generell intelligens man kan nå bara genom att lära en AI ett språk. (Sen tror jag att visuell data och gärna en fysisk robot behövs för att nå hela vägen, men det är spännande forskning att se hur långt man kommer enbart med språket.)
Du missar nog lite av sammanhanget mitt inlägg skrevs i.
ChatGPT har oberoende syfte tagits emot av Världen som det var en stor verktygslåda som redan nu kan ersätta saker, allt från uppslagsverk och Google till människor i deras yrkesroller.
Intresset har fullkomligt exploderat och det har skrivits mängder av hyllande artiklar och varnande artiklar om hur skolelever kan fuska utan att lärare kan upptäcka plagiat.
Min kavalakad av exempel var en motvikt mot detta för att visa hur opålitlig den är, hur den hittar på saker och rent av i vissa fall hittar på källhänvisningar.
Sorry, jag har inte fört register över var saker stått, men det finns ca 17 000 000 artiklar om chatgdp på google news, så någonstans där kan jag pinpointa det till.
Inga problem. Det handlar om hur uppgifter formuleras. Mer och mer forskning visar även på vikten av att inte arbeta digitalt för att främja utvecklingen.
Miniräknaren är ett verktyg. Du behöver veta hur och när det skall användas och när det inte fungerar. Miniräknaren lär dig inte matematik, den kan i vissa sammanhang underlätta räknandet. Den gör dock bara det du ber den om och du måste veta vad du skall be den om och på vilket sätt. Gör du det fel, kommer du få fel svar tillbaks. Om du inte kan matematiken så vet du inte om att du fått fel svar, vilket kan få jobbiga konsekvenser beroende av vad du ville göra från början.
Jag vet inte. Redan på OpenAIs hemsida står det så här i första punkten av begränsningar:
"Limitations
ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers. Fixing this issue is challenging, as: (1) during RL training, there’s currently no source of truth; "
Detta är ju precis som i tidigare versioner. Det är typiskt för RL vs formella metoder till att representera kunskap.
Detta känner jag är något som låter bra men omöjligt att applicera in verkligheten.
Hur ska du kunna veta om x% per år i y år är bättre än y% i x år utan att räkna exakt? Eller hur ska du veta om det är värt att satsa a kronor på ett projekt som kommer ge b antal mer kroner pretty år i c antal år? Detta är enormt svårt att räkna ut, hur ska du då bedöma om du får hel eller rätt svar? Kör på känsla? Är det så man borde göra i ränta-på-ränta?
Att anta att människor ska förstå vad som är rätt eller fel svar närmast omänskligt!
En intressant tanke är hur ofta detta gäller människor också. Hur många gånger har en människa bara “nästan” rätt, och hur stor roll spelar skillnaden mellan 100% rätt och 80% rätt? Jag tänker att en stor del av tiden på många arbeten går åt till att rätta till mindre fel eller göra justeringar av andra människors arbete. I en arbetsgrupp så produceras små fel hela tiden men det gör inget för antingen så är det inte så noga, eller så upptäcks det och rättas till.
Vart går gränsen för när mängden fel blir ett hinder? Vill du ha en junior kollega som löser 5 uppgifter per dag 99% rätt, eller en som löser 100 uppgifter per dag 80% rätt?
Jag försöker alltid kriga lite mot sådan här inställning. Jag skulle säga exakt tvärt om. Hur folk generellt reagerar och recenserar saker som är svåra att ta till sig har inte alls samma signifikans som informationen som kommer direkt från forskarna. Ännu bättre är såklart rapporten själv, men OpenAI brukar vara bra på att kommunicera vad som är nytt och vilka begränsningar som finns i deras experiment.
Jag håller med om att detta inte har något med kunskaps representation att göra. Det går inte att använda som uppslagsverk.

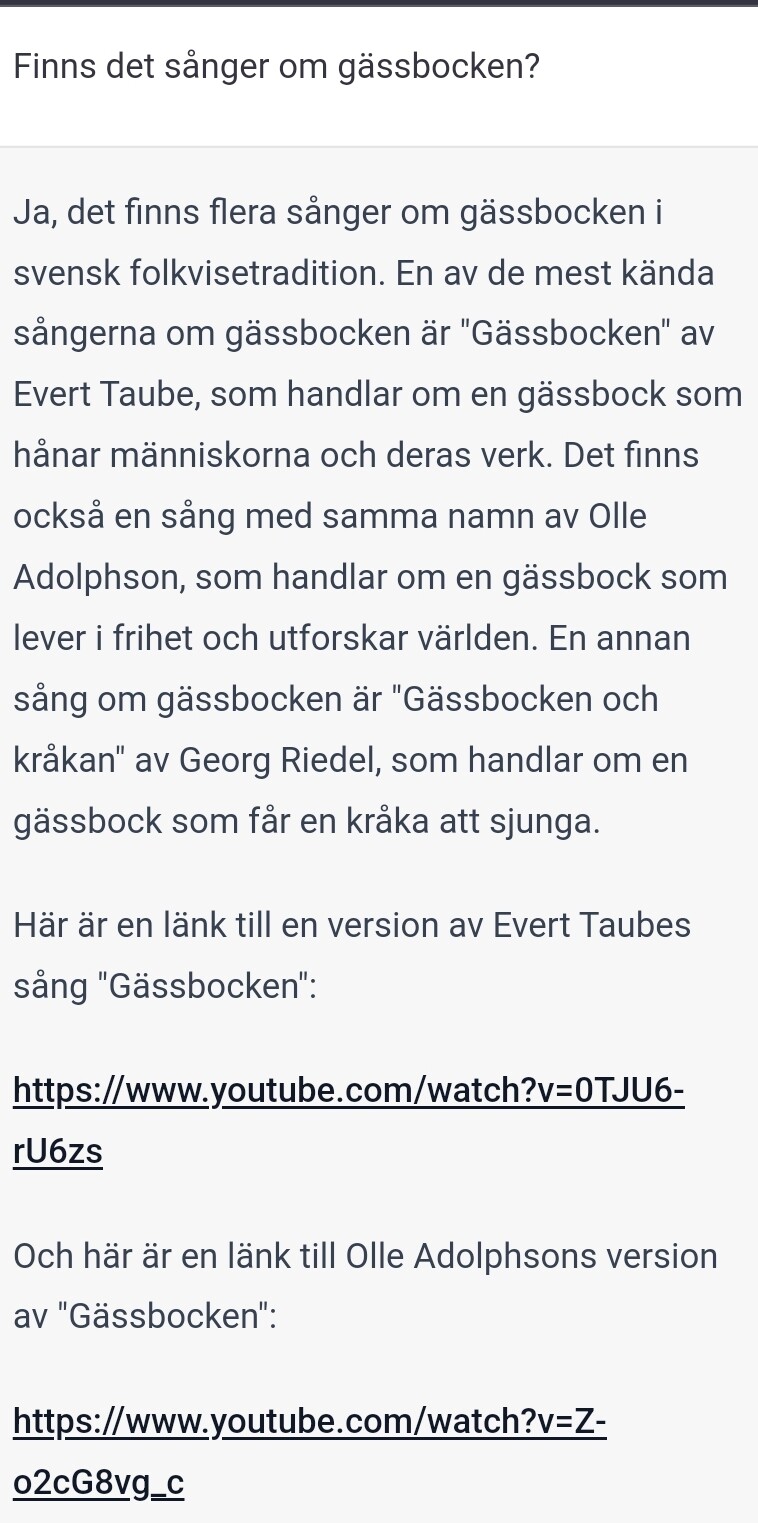
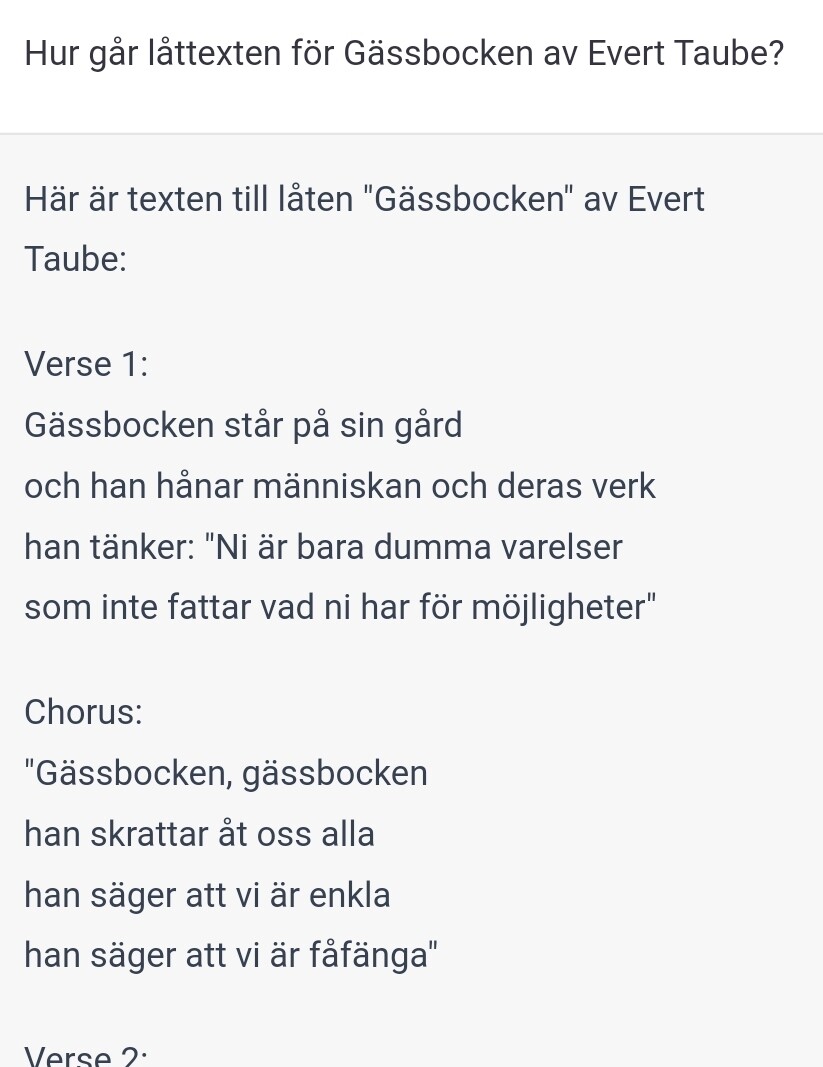
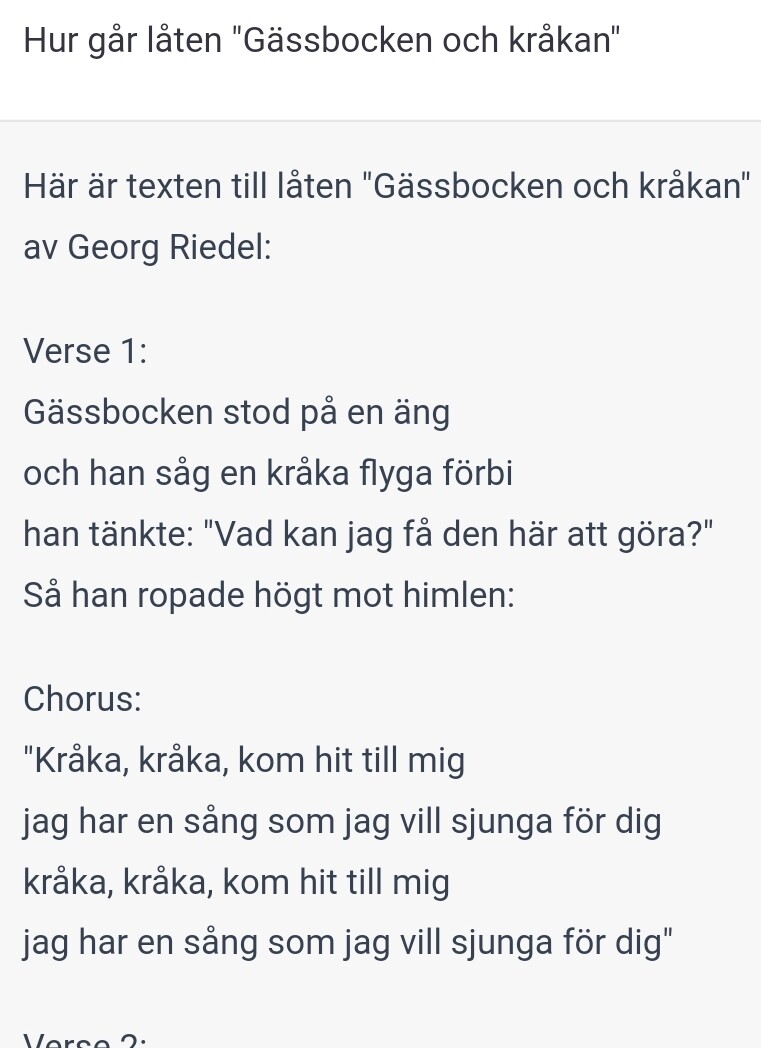
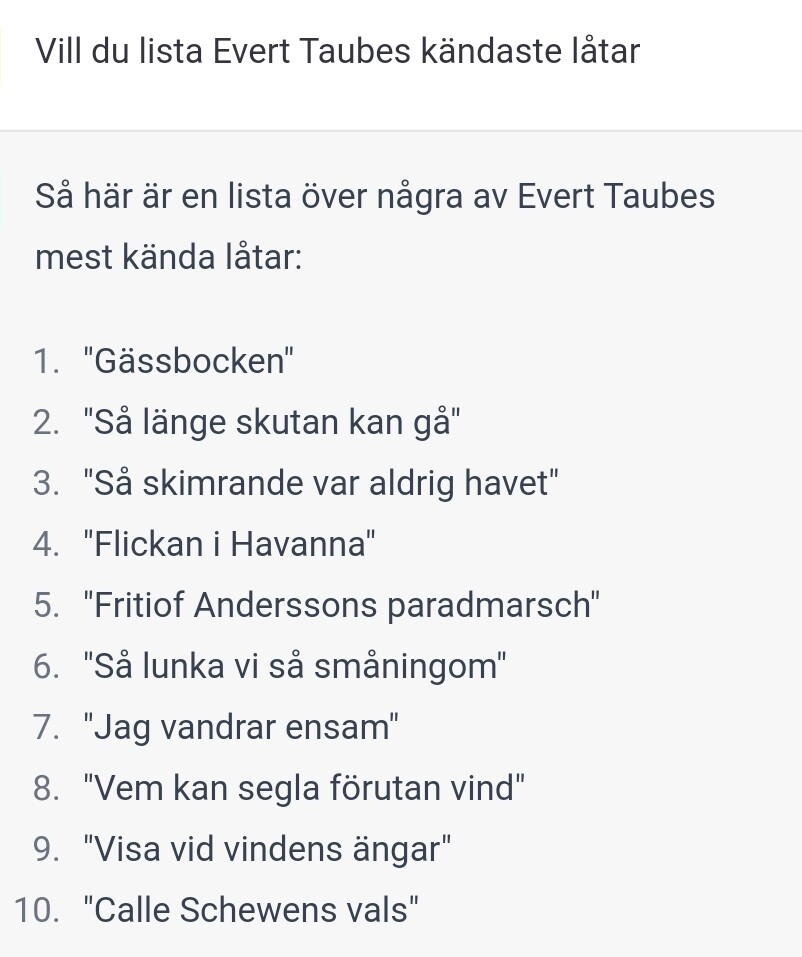
 ingen fara
ingen fara
 Tack för den.
Tack för den.