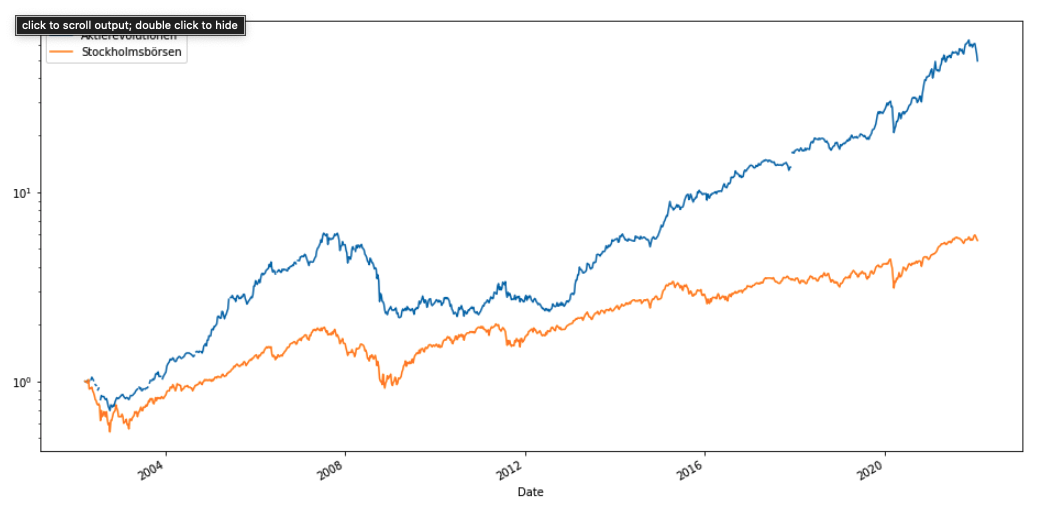
Och här är samma plot med logaritmisk skala.
Vänligen notera:
- Det jag visar här är resultatet av simuleringar på aldrig tidigare sedd data. Det vill säga: Min modell har tränats på svensk data och därefter testats på dansk och finsk data.
- En portfölj börjar med 10.000 kr och därefter tillskjuts inget kapital.
- Portföljen betalar courtage i paritet med bästa courtageklassen på Avanza vid varje given stund.
3 gillningar
Jag förstår inte din invändning. Man kan inte sia och se in i framtiden, nej. man kan inte påstå att något kommer att gå bra. Det kan man aldrig göra.
Vad har det med min strategi att göra?
Några saker som vissa ger uttryck för i olika ordalag och som jag gärna svarar på en gång för alla:
"Om din strategi nu är så himla grym, varför säljer du den då så billigt?"
Jag säger inte att min strategi är “så himla grym”. Jag säger att jag har en spännande strategi som förhoppningsvis är grym. Därav frågeställningen. Därav det experimentella och därav ett pris som börjar på en väldigt låg nivå på de som är med tidigt. Man måste börja någonstans om man inte har några kunder!
"Varför startar du inte bara en fond?"
Av samma anledning som jag inte byggen en skyskrapa. Jag har inte en massa miljoner som ligger och skräpar. Tyvärr.
1 gillning
Att det inte är nån skillnad på att vänta 10 år eller backtesta nu.
Det är två ekvivalenta saker.
Så det du skriver om att en strategi som “bevisligen” har bättre riskjusterad avkastning än börsen är värd pengar, medans din inte är det då den saknar track record inte riktigt håller.
För du kan lika gärna använda fiktivt trackrekord på historisk data givet att det inte är träningsdata. Det är lika värdefullt (eller lika värdelöst om man så vill).
Därför jag påpekar det tempus du använder (har) inte går att visa med metoden och skrev haft.
Så om man inte kan se in i framtiden (vilket vi båda är överrens om) så går det inte heller att visa att en strategi har en viss överavkastning. Har är desamma som att se in i framtiden i denna tillämpning.
Jag förstår inte heller varför du inte startar fond eller säljer strategin till ett fondbolag. Kapitalet som krävs kommer de kasta på dig om de ser en potential. Det är inget du behöver ha personligen eller så.
Tack, det är jättebra idéer!
Kruxet är att strategin då blir mer komplicerad. Min målsättning är att vem som helst ska kunna följa den på typ 5 minuter i veckan.
Skulle man t.ex. inkorporera en “säljlista” också så skulle den kunna innehålla hundratals aktier. Helt plötsligt är det inte så kvickt och lätt längre.
Du har helt rätt. En del aktier ligger och “skvalpar” och är inte de som genererar vinst vecka efter vecka. Dessutom är det inte så säkert att det är det bästa att sälja av dem. Jag citerar Buffet igen:
“The first rule of an investment is don’t lose money . And the second rule of an investment is don’t forget the first rule.
Alltså: om man realiserar förluster med jämna mellanrum så har man kanske uppförsbacke. Det skulle man i så fall behöva kolla närmare på.
Intressant projekt du har startat upp! Jag vill gilla det. Tycker om att du kört och nu testar det i skarpt läge. Samtidigt har jag invändningar och … mitt svar på din fråga är nej. Jag tror inte på att det går att slå index på 5 minuter i veckan med det du säljer.
Avanza/Placera har sen flera år ett samarbete med ett norskt företag som lever på att sälja teknisk analys till investerare som oss här på forumet. Jag roade mig med att se vad de rekommenderat och hur det gått närmaste perioden efter deras rekommendationer. Det roliga jag upptäckte var att det de satt KÖP på har givit negativ avkastning och det omvända för det de satt SÄLJ på. Här är bara två av deras senaste köpta artiklar. Är det anekdotiska bevis? Ja visst. Pekar det i att TA inte fungerar? Kanske.
Jag tror att vi är eniga till … 90%.
Jag håller helt med dig om tempus i den citerade meningen.
Jag håller inte med dig om att det är ekvivalent att ha ett live track reckord i verkligheten och att ha backtestat. Jag antar att du menar att man delar upp sin data på tid i ett träningsset och ett testset och att resultatet på testsetet är lika värdefullt som om man kört live ett tag? Då är man offer för egna antaganden och förenklingar, för att inte tala om buggar i kod och det faktum att man inte påverkat den marknad man handlat i. Bara riktigt är riktigt.
Jag förutsätter att du inte menar att man ska träna och utvärdera på samma data…
Jag ser heller inte hur man pitchar det till en fond. Men jag kan ha fel. Jag hoppas nästan det.
1 gillning
10X bättre utveckling gör att varningssignaler borde ringa. Och det leder in på fenomenet overfitting, där man bara tittar tillbaks på en viss tidshorisont och skapar en algoritm som passar för bra till den träningsdata man använder, som därmed misslyckas totalt när man ska titta framåt.
Det här är ett extremt vanligt problem, speciellt inom forskning om AI och machine learning.
8 gillningar
Ja det är ju en förutsättning. Om du gör den uppendelningen där testsetet är de senaste 10 åren och träningssetet är datan innan. Då är det helt ekvivalent med med att köra skarpt i 10 år och använda all data fram till idag som träningsdata.
Om 10 år får du då ett dataset i form av testdata som är 10 års historik och ett träningsdataset som är datan fram till för 10 år sen.
Om du någon gång under dessa 10 kommande åren gör någon som helst ändring efter resultatet. Så har du direkt gjort en del av testdatasetet till träningsdata och får vänta 10 år till.
Det är du oavsett om du kört “skarpt” en period eller inte.
Vad gäller buggar och dylikt är du inte imun mot det ändå. Där får du ta fram mjukvarutester som verifierar programmet oavsett. Det är ju väldigt enkelt att skriva tester då du kan generera fakead testdata väldigt enkelt.
Ta kontakt med ett bolag som driver Hedgefonder får du se om de är intresserade av att köpa din algoritm. Implementationen lär de göra om ändå.
2 gillningar
Innehåller det historiska datat som du kört dina simuleringar på även bolag som inte längre är noterade på börsen? Om inte är jag rädd att dina simuleringar kan bli lite missvisande. Det är också så att ju fler som följer en viss strategi desto sämre fungerar den. Särskilt om strategin köper och säljer illikvida bolag. Har du räknat med courtageavgifter? Vilka köp och säljkurser räknar du med? Är det stängningskurserna?
Först, jag uppmuntrar all slags experimenterande. Många bra saker man lär sig genom att arbeta sig genom problem som dessa.
Du säger att du validerat på osedda data. Viktigt då är att förtydliga om du har tagit fram en modellstruktur, optimerat parameterar, och sedan validerat på osedd data.
Ett vanligt fel jag ofta ser (eller rättare sagt inte ser eftersom det inte tydliggörs) är att man valt en modellstruktur, optimerat parameterar, validerat på testdata och tyvärr sett att det inte funkat bra, och då gått tillbaka och funderat fram en ny modellstruktur och repeterat. Man har då inte validerat på osedd data, utan har bara gjort en hierakisk uppdelning av optimeringen på träningsdata. En inre loop som man optimerar numerisk på en viss testdata, och en yttre loop som man hanterar manuellt genom att förkasta dåliga modeller på annan testdata. Ganska snabbt blir detta datafiske och tyngden av valideringsresultatet ganska svagt.
9 gillningar
Kul projekt!
Jag vet inte exakt vad för sorts data du validerat mot, men som nämnts tidigare i tråden så skulle jag oroa mig mest över möjligheten till overfitting. Så länge som framtiden ser ut som historien så kommer algoritmen säkert prestera väl. Men så fort den möter en situation den inte sett tidigare så finns alltid en överhängande risk att den kommer börja bete sig som den totala idioten den egentligen är. Det är ju inte för intet som många kvantfonder brukar fungera svinbra…ända tills de inte gör det.
1 gillning
Precis. Jag skulle inte heller hoppa på en strategi som bara är testad på data från de senaste 20 åren. Det är alldeles för lite.
1 gillning
Skillnaden i praktiken är väl dock att det för en utomstående är lättare att lita på resultatet från det förra snarare än det senare. Du kan lova dyrt och hederligt att du inte har gluttat på valideringsdatasetet och att du sedan bara testat på det en enda gång, men för mig som utomstående så är det omöjligt att verifiera att så är fallet. Om någon publikt visar sina förutsägelser och sedan inväntar resultatet så vet jag att personen i fråga i alla fall omöjligen kan ha sysslat med overfitting.
Hade du köpt en svart låda som en gång i veckan printar ut en lapp med vilka aktier som du ska köpa och sälja, även om du kan se hur den har presterat i 10 år?
När du måste lita på att den som säljer dig lådan lovar dyrt och heligt att hen inte ändrat något alls i den under dessa 10 år? Om du inte har full insyn i den så måste du ju lita på den som har algoritmen inte har ändrat något i den.
Dock så får du ju survivorship bias då kan ha funnits många “lådor” varav just denna som har 10 års historik är den som överlevt (med bra historik).
5 gillningar
1, först vill jag tacka för att sådan som du gör ett jobb så att vi indexinvesterare kan njuta av hög risk justerad avkastning till låg avgift 
2, om din algoritm skulle bli bra och populär så skulle man troligen kunna tjäna sig en hacka på att prenumerera och blixtsnabbt köpa innan dina följare hann trycka upp kursen. Det skulle förvisso leda till att Svensson som enbart vill läsa 5 min per vecka inte skulle kunna tjäna några pengar eftersom de snabbfotade redan skulle ha tryckt upp kursen.
3, skulle någon annan algoritm kund utnyttja din tjänst som en del av sin inmatning? Har du planerat för det?
4, hur hindrar du är någon prenumererar på din tjänst och inte lägger upp det online? Finns det någon copyright? Fungerar copyright ens med aktieanalyser?
1 gillning
Kanske. Om det bevisligen åtminstone har funnits en algoritm som har presterat bra i tio år och jag på något sätt kan sluta mig till att den som säljer svarta lådan idag har någon slags koppling till den som sålde svarta lådan igår så finns det i alla fall någon slags indicie på att försäljaren har någon slags koppling till någon (vilket kan vara samma person som försäljaren) som åtminstone vid något tillfälle kunnat göra bra förutsägelser. Sätt detta i kontrast till att overfitta en modell, något som jag skulle kunna göra på en timme nu.
Sedan har jag aldrig påstått att detta i sig räcker för att man ska slå till. Jag påstår bara att i praktiken så kommer det finnas en relevant skillnad för utomståendes förtroende mellan att kolla 10 år bak i tiden och att vänta 10 år, vilket var originalpåståendet som jag replikerade på.
Absolut. Jag valde att inte plocka med detta resonemang för att inte krångla till det i onödan. Skillnaden är dock att om personen har skapat hundratals aktierobotar så finns det i alla fall en större chans för mig att hitta dessa och avslöja felet jämfört med exempelet då jag inte har någon insyn alls. Jag säger inte att det är bra, men i alla fall bättre. Åter igen, att overfitta en modell kan jag göra helt utan att någon någonsin skulle ha ens en teoretisk möjlighet att avslöja mig (givet att de typ inte installerat en trojan på min dator och spionerat på när jag arbetat ![]() ).
).
Dock var min poäng inte direkt relaterat till att sälja utdatan av en sådan här modell. Utan snarare hur bevisvärdet för “kommande” historik och backtestad historik är i praktiken desamma. Givet att ingen är en bedragare.
Alltså för att antingen bevisa för sig själv eller en potentiell köpare av algoritmen/modellen. Det är ju väldigt enkelt att göra en överenskommelse med en köpare av algoritmen att om “fuskdata” använts för validering så återgår köpet. Då vet ju både säljaren och köparen att datan som använts är “korrekt” i meningen att den har körts på 10 års “färsk” historik.
Ja, givet att ingen är en bedragare så är det naturligtvis så (så länge som man också lyckas att inte omedvetet påverkas av saker som man känner till om hur aktiemarknaden har gått de senaste tio åren). Men från TS sida så är det absolut viktigt för hen att visa att hen inte är någon bedragare och då skulle jag alltså säga att det är en mycket bättre strategi att visa på hur algoritmen går efter att den gått live snarare än att visa på hur den skulle ha kunnat gått under en tid innan den gått live.
Frågan är dock hur man någonsin skulle kunna bevisa att fusk förekommit (vi behöver ju inte prata om galen overfitting som gör det mer eller mindre helt uppenbart). Problemet finns ju exempelvis inom många vetenskaper där man på det stora hela kan säga med rätt hög säkerhet att det förekommer forskningsfusk med avseende på dessa saker utan att för den sakens skull kunna peka ut någon enskilld studie där man med säkerhet kan säga att det förekommit.