Hej!
Det här är mitt första inlägg med denna pseudonym, men har hängt på forumet tidigare. Jag skulle vilja dela med mig av vad jag har hittat.
Först så skulle jag vilja ge lite bakgrund. Jag har hållit på med att utveckla investeringsalgoritmer sedan 2011 och har testat otaliga varianter och köpt och sålt aktier, etf, fonder och mini long/shorts på vägen. Därtill har jag skannat internet efter matnyttigt material och spännande koncept att bygga vidare på.
Jag har landat i nästan samma grundbult som de flesta här på forumet skriver på, att indexfonder/etfs är ett enkelt sätt att få bra riskspridning. Problemet, som ni alla vet - är att det är svårt att sitta på händerna när skiten träffar fläkten och båten gungar. Alla aktier samvarierar mer eller mindre, det finns sällan något skydd när marknaden klappar ihop som den gjorde 2008, 2011 och 2020.
Efter många år av sökande så tror jag har hittat ett sätt att ta upp båten på land när det stormar. Det gör det ju ibland på marknaden. Med de verktyg jag hade så byggde jag upp en relativt okomplicerad algoritm (tänk första mattekursen på gymnasiet ungefär) som jämför räntor mot index och verkar ge relativt god kausalitet, dvs att den kan förutspå när en sämre investeringsperiod är på ingång. Jag har testat att fördröja signalen med olika antal dagar, och signalen är ändå stark.
Nåväl. Såhär ser det ut för OMXS30 när jag applicerar algoritmen bakåt. Portföljen är likvid när vi är utanför börsen. Vän av ordning säger såklart att man kan inte investera i ett index, men det ger i alla fall en antydan av vad exempelvis xact omxs30 skulle ha gett.
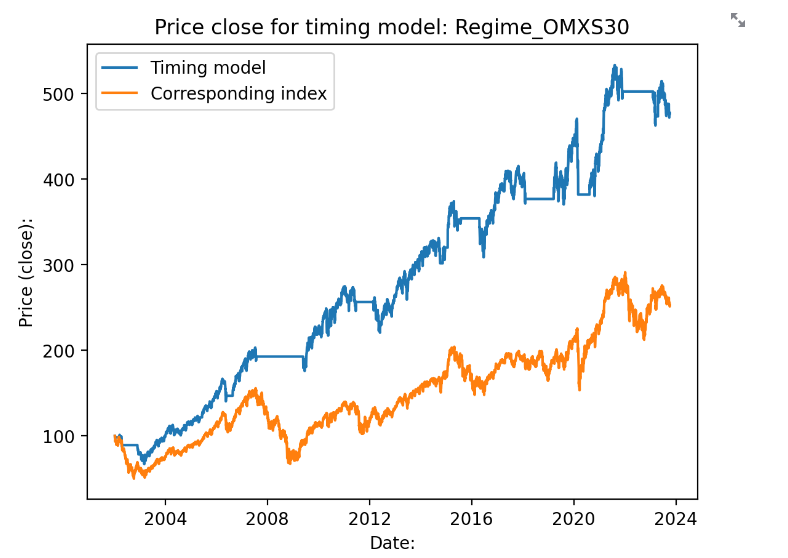
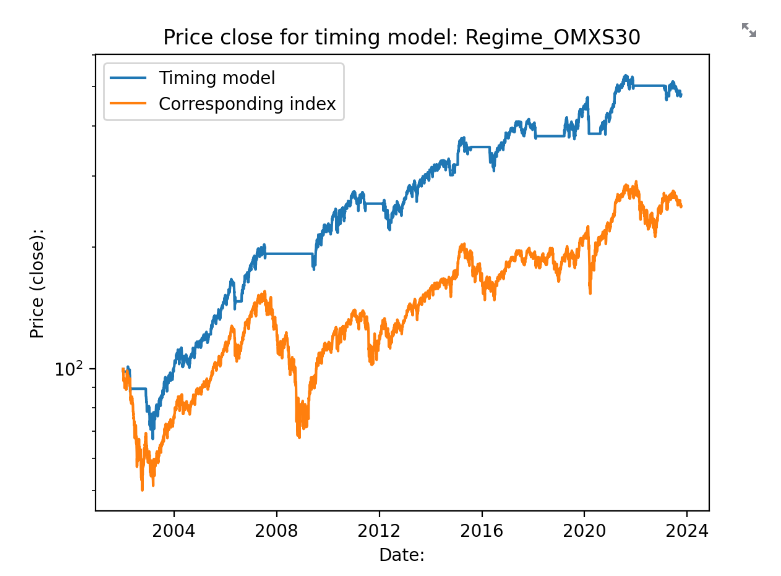
Vi hamnar då på ca 377% avkastning på 21 år, eller ca 7.45% årlig avkastning. Helt okej med tanke på att vi 35% av tiden inte tar någon risk alls. Notera att vi också börjar mitt i IT-bubblan, vilket algoritmen parerar någorlunda. Tyvärr så sträcker sig inte min data längre än så för OMXS30. Avkastningen för indexet utan timingmodellen ligger på 152%, så avkastningen är mer än dubbelt så stor för denna tid. Logaritmisk skala nedan:
Skulle portföljens värde läggas i ett sparkonto under tiden som vi är likvida så skulle avkastningskurvan se ut såhär:
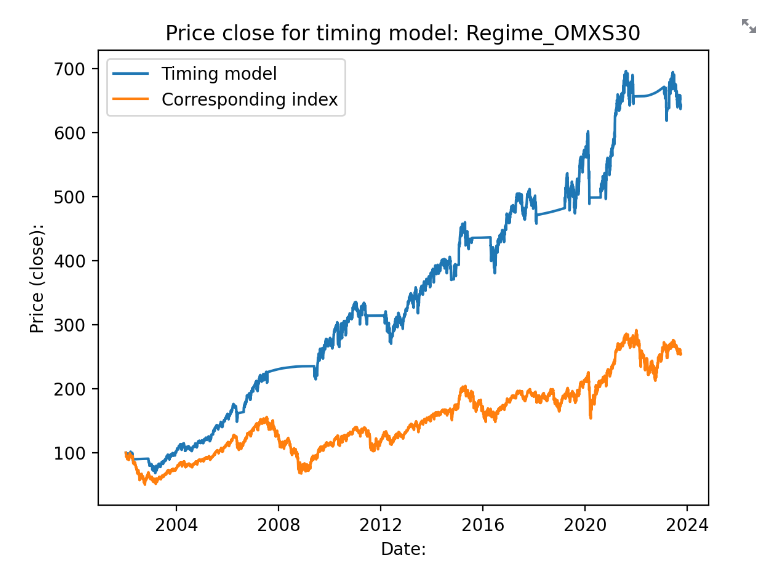
Istället för 377% avkastning hamnar vi på 541%, eller 8.9% årlig avkastning. Sparkontot har jag satt till Fed funds effective rate, dvs amerikanska centralbankens utlåningsränta. Det finns skäl att tro att man skulle kunna ha större ränta än så på sitt sparkonto, men också mindre (det är ju 30% skatt i sverige). Det är främst för att kunna få ut en ungefärlig snittränta på ett sparkonto.
Tittar man på sharpekvoten hamnar vi på 0.6 och sortinokvoten på 0.94. Vi snittar dubbelt så många transaktioner per år, då vi även behöver flytta pengarna till ett sparkonto/räntekonto. Därför hamnar vi i snitt på 3 stycken transaktioner per år.
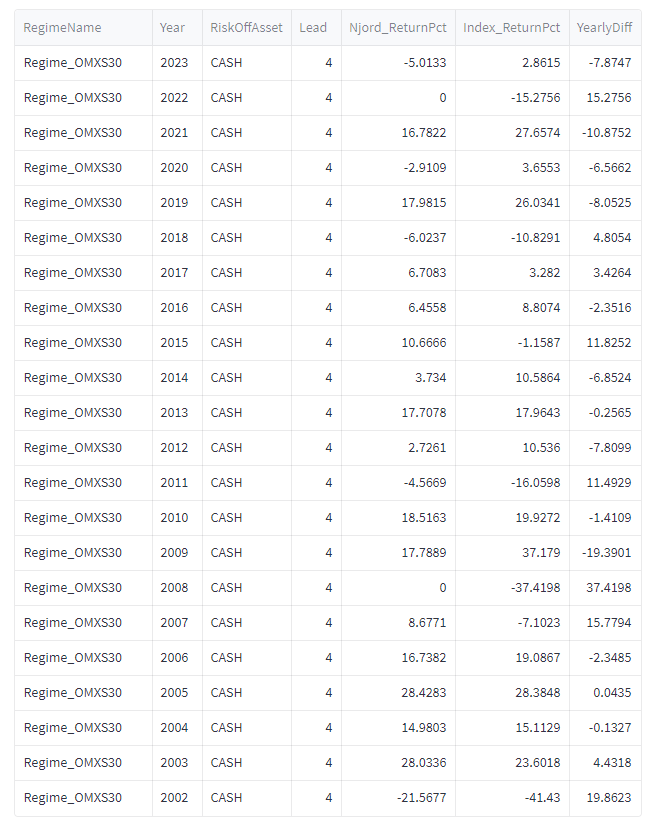
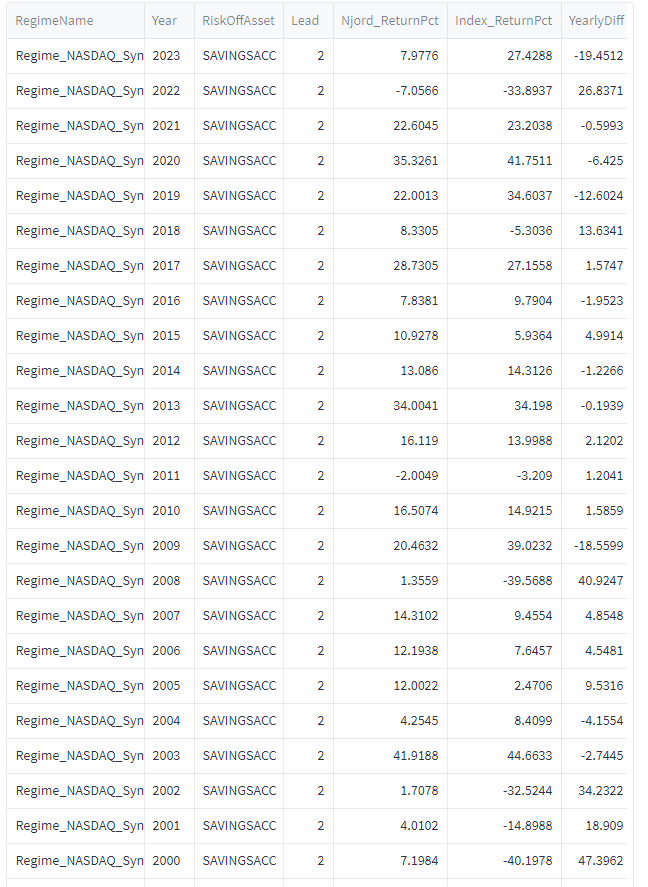
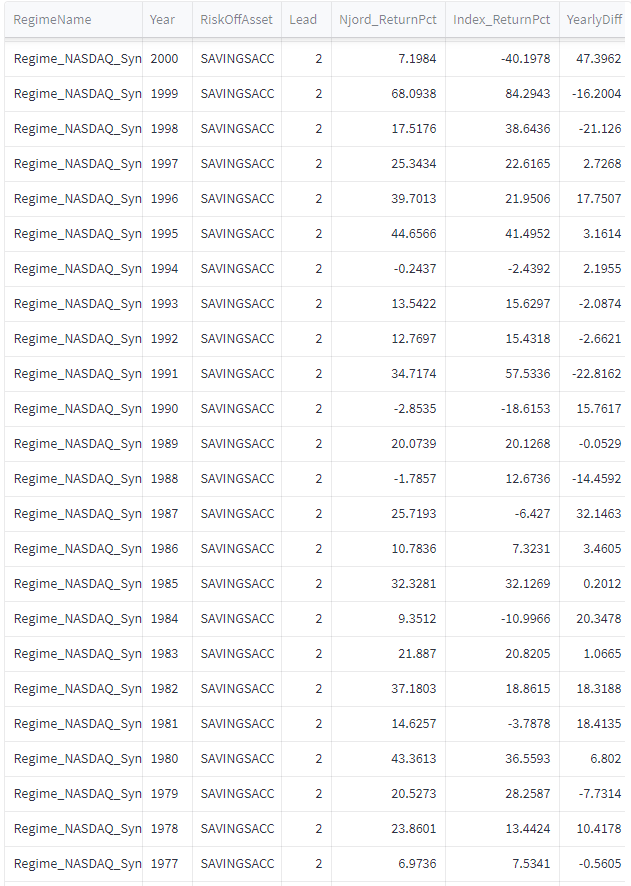
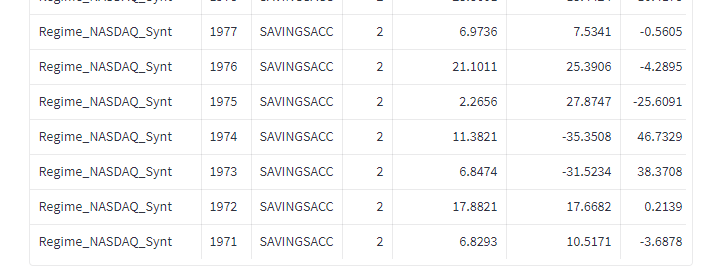
Så här ser utvecklingen ut för timingmodellen utan sparkonto om vi tittar årsvis. Njord är algoritmens namn. Lead = 4 betyder att vi 4 dagar efter signalen gör en transaktion. YearlyDiff visar skillnaden mellan Njord och buy-and-hold av indexet. Positiv YearlyDiff visar att algoritmen slår indexet.
Och såhär ser den ut om vi tittar per transaktion. TimingReturns visar vad det tidigare köpet ger för avkastning.
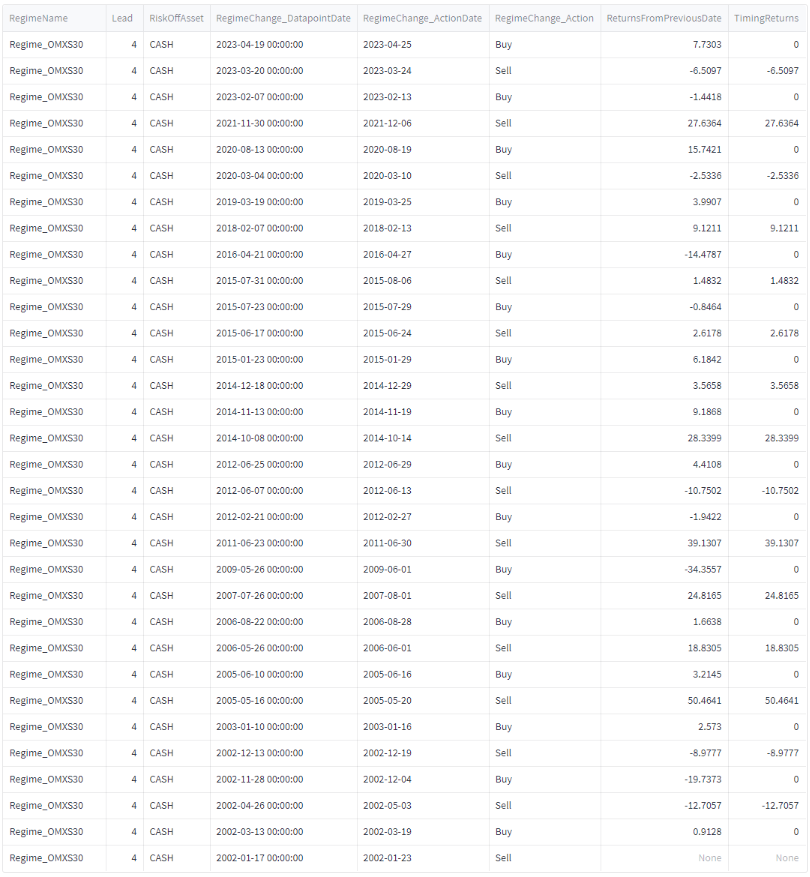
Jag har mer historisk data för Nasdaq och SP500. För Nasdaq så får vi en klassisk hockeyklubba:
Jag tror att Nasdaq blir så bra för att den är lite lagom bubblig av sig, det är större uppgångar, men också större nedgångar.
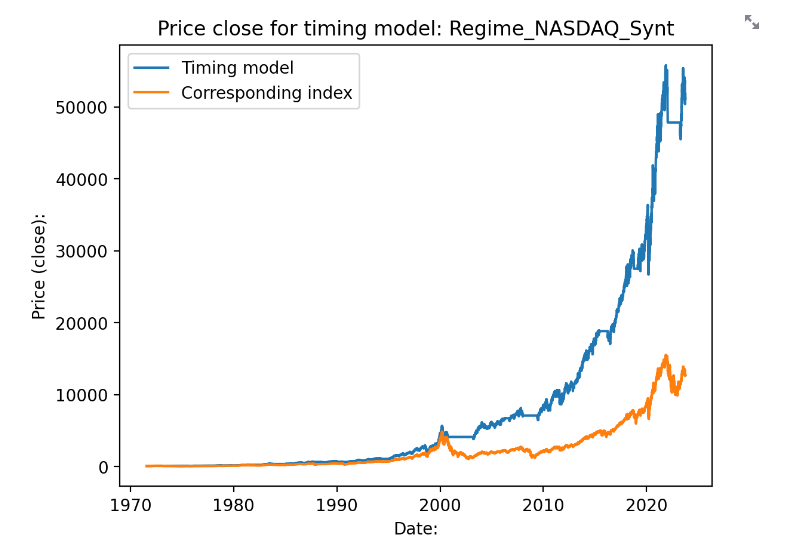
En ännu trevligare kurva får vi om man också använder sig av ett sparkonto istället för att hålla pengarna arbetslösa:
Och som logaritmisk skala: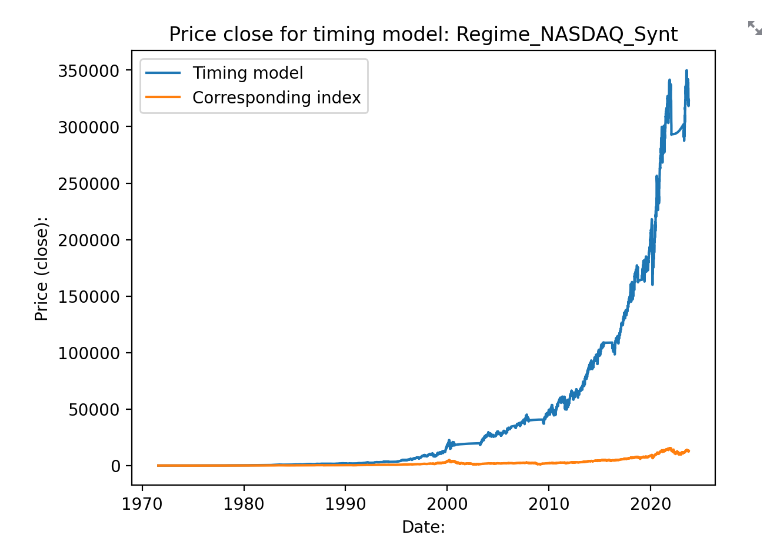
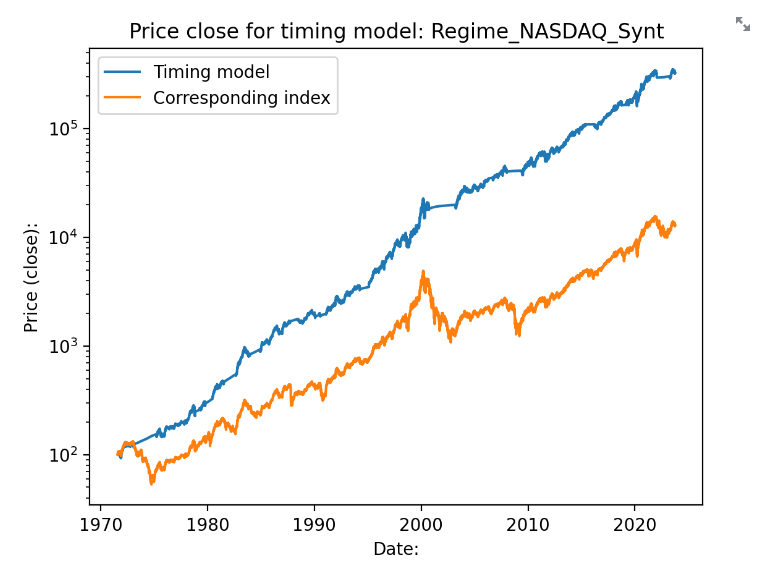
Då blir avkastningen 16.7% per år i snitt. Sharpekvoten hamnar på 1.18 och sortinokvoten på 2. Med sparkontot så hamnar vi på i snitt 2.6 transaktioner per år. 5 av 51 år så går algoritmen minus med detta upplägg: 1988 (-1.78), 1990 (-2.85), 1994 (-0.24), 2011 (-2.00) samt 2022 (-7.05). 31 år av 52 så går algotitmen bättre än indexet. Det är främst duckandet av de stora breda nedgångarna som gör störst skillnad.
Avkastning per år:
Det mer “normala” indexet SP500 får också en bra utveckling över 52 års tid:
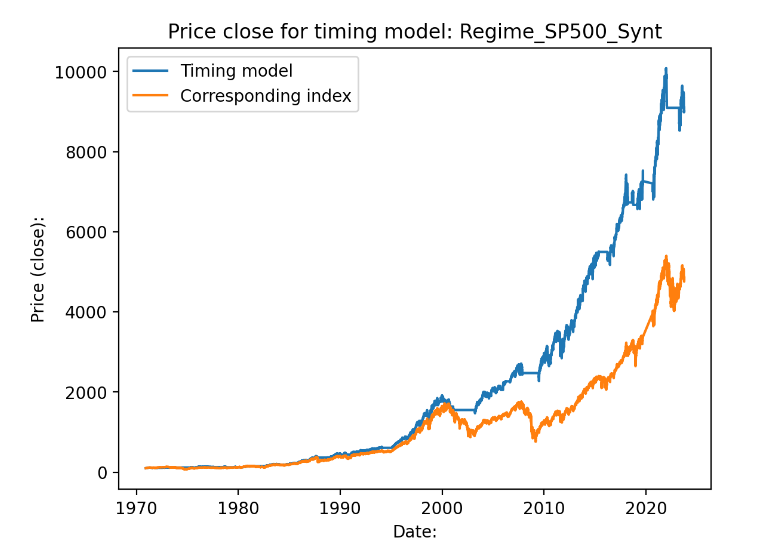
Logaritmisk skala:
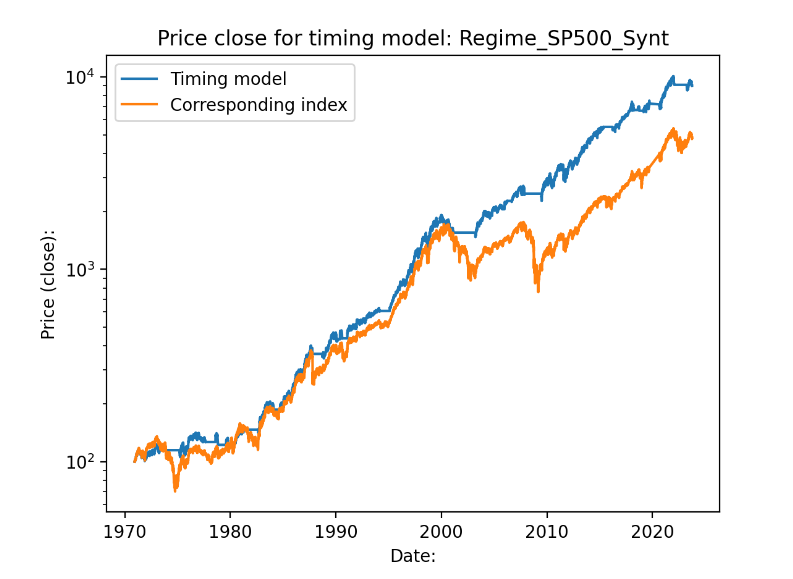
Och särskilt med ett sparkonto att gå över till när dipparna kommer. Högräntemiljön på 70- och 80-talet får en bra boost när börsen gick ner under denna tid, räntan på sparkontot var ibland över 10% dessa år.
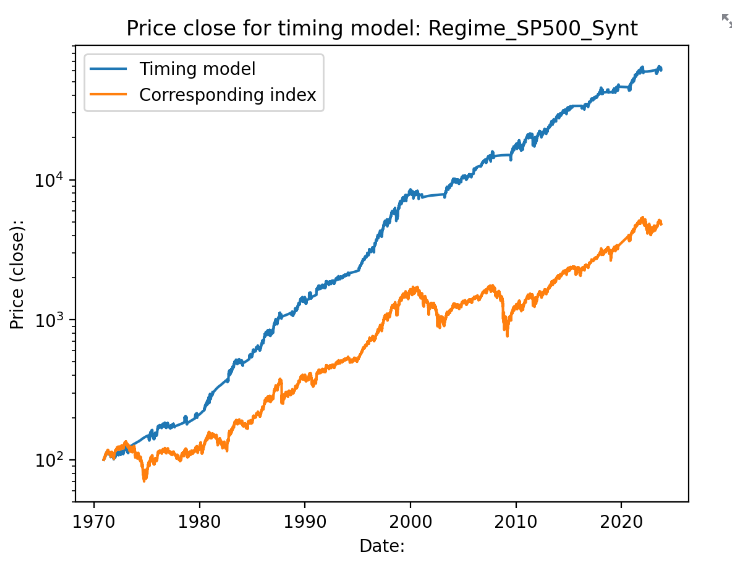
Här landar vi på 13% i årlig avkastning, Sharpe på 1.05, Sortino på 1.84 och maximal drawdown på ca 19%.
Jag har lagt in x antal släpande dagar (vanligtvis 2,3 eller 4) för att undvika lookahead bias. Transaktionskostnaden borde bli ganska låg med tanke på att det händer så sällan. Direktavkastning är inte medräknat, men kanske kan “dras av” mot skatt och andra kostnader?
Så vad tycker ni? Jag tycker i alla fall att jag träffar dipparna bra och att det finns kausalitet mellan signal och framtida utveckling, särskilt för amerikanska index.
Edit: daglig uppdatering av algoritmen finner ni här: https://www.indexweather.com